What is Apache Spark?
Apache Spark is an Open source analytical processing engine for large scale powerful distributed data processing and machine learning applications. Spark is Originally developed at the University of California, Berkeley’s, and later donated to Apache Software Foundation. In February 2014, Spark became a Top-Level Apache Project and has been contributed by thousands of engineers and made Spark one of the most active open-source projects in Apache.
What is PySpark?
Before we jump into the PySpark tutorial, first, let’s understand what is PySpark and how it is related to Python? who uses PySpark and it’s advantages.
Introduction
PySpark is a Spark library written in Python to run Python applications using Apache Spark capabilities, using PySpark we can run applications parallelly on the distributed cluster (multiple nodes).
In other words, PySpark is a Python API for Apache Spark. Apache Spark is an analytical processing engine for large scale powerful distributed data processing and machine learning applications.

Spark basically written in Scala and later on due to its industry adaptation it’s API PySpark released for Python using Py4J. Py4J is a Java library that is integrated within PySpark and allows python to dynamically interface with JVM objects, hence to run PySpark you also need Java to be installed along with Python, and Apache Spark.
Additionally, For the development, you can use Anaconda distribution (widely used in the Machine Learning community) which comes with a lot of useful tools like Spyder IDE, Jupyter notebook to run PySpark applications.
In real-time, PySpark has used a lot in the machine learning & Data scientists community; thanks to vast python machine learning libraries. Spark runs operations on billions and trillions of data on distributed clusters 100 times faster than the traditional python applications.
Who uses PySpark?
PySpark is very well used in Data Science and Machine Learning community as there are many widely used data science libraries written in Python including NumPy, TensorFlow. Also used due to its efficient processing of large datasets. PySpark has been used by many organizations like Walmart, Trivago, Sanofi, Runtastic, and many more.
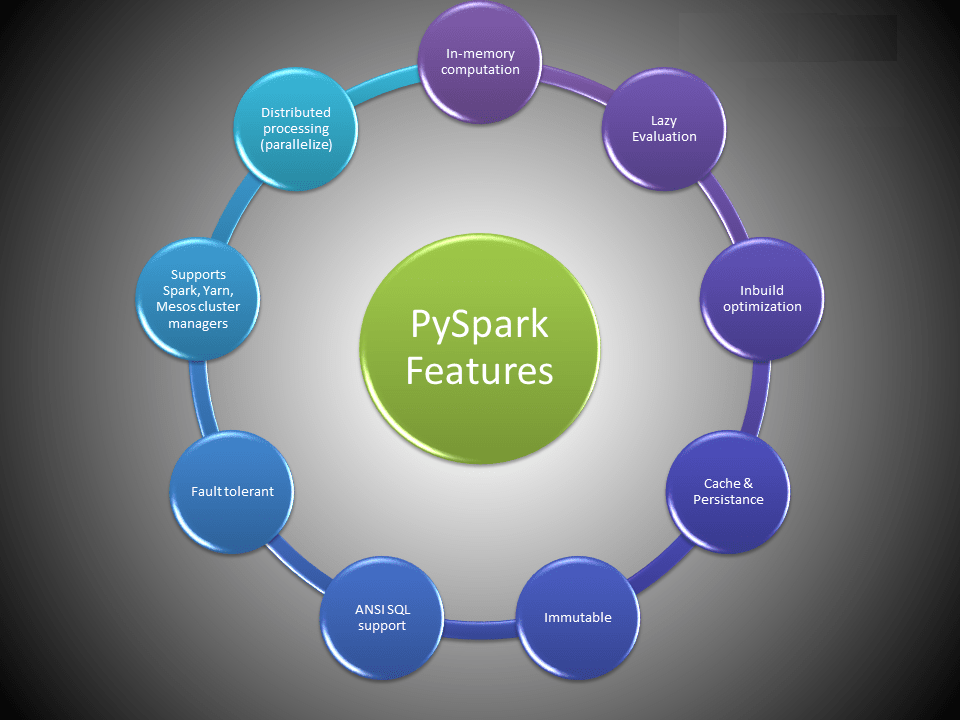
Apache Spark Features
- In-memory computation
- Distributed processing using parallelize
- Can be used with many cluster managers (Spark, Yarn, Mesos e.t.c)
- Fault-tolerant
- Immutable
- Lazy evaluation
- Cache & persistence
- Inbuild-optimization when using DataFrames
- Supports ANSI SQL
Apache Spark Advantages
- Spark is a general-purpose, in-memory, fault-tolerant, distributed processing engine that allows you to process data efficiently in a distributed fashion.
- Applications running on Spark are 100x faster than traditional systems.
- You will get great benefits from using Spark for data ingestion pipelines.
- Using Spark we can process data from Hadoop HDFS, AWS S3, Databricks DBFS, Azure Blob Storage, and many file systems.
- Spark also is used to process real-time data using Streaming and Kafka.
- Using Spark Streaming you can also stream files from the file system and also stream from the socket.
- Spark natively has machine learning and graph libraries.
Apache Spark Architecture
Apache Spark works in a master-slave architecture where the master is called “Driver” and slaves are called “Workers”. When you run a Spark application, Spark Driver creates a context that is an entry point to your application, and all operations (transformations and actions) are executed on worker nodes, and the resources are managed by Cluster Manager.
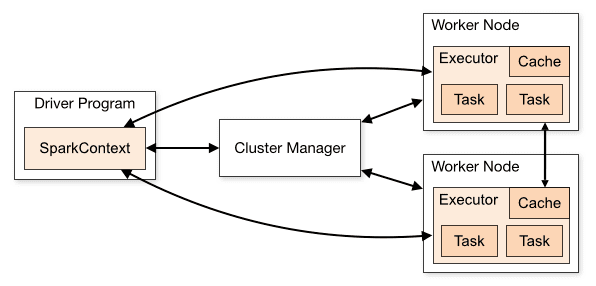
Cluster Manager Types
As of writing this Apache Spark Tutorial, Spark supports below cluster managers:
- Standalone – a simple cluster manager included with Spark that makes it easy to set up a cluster.
- Apache Mesos – Mesons is a Cluster manager that can also run Hadoop MapReduce and Spark applications.
- Hadoop YARN – the resource manager in Hadoop 2. This is mostly used, cluster manager.
- Kubernetes – an open-source system for automating deployment, scaling, and management of containerized applications.
local – which is not really a cluster manager but still I wanted to mention as we use “local” for master() in order to run Spark on your laptop/computer.
Spark Installation
In order to run Apache Spark examples mentioned in this tutorial, you need to have Spark and it’s needed tools to be installed on your computer. Since most developers use Windows for development, I will explain how to install Spark on windows in this tutorial. you can also Install Spark on Linux server if needed.
Download Apache Spark by accessing Spark Download page and select the link from “Download Spark (point 3)”. If you wanted to use a different version of Spark & Hadoop, select the one you wanted from drop downs and the link on point 3 changes to the selected version and provides you with an updated link to download.
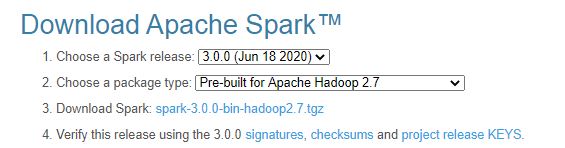
After download, untar the binary using 7zip and copy the underlying folder spark-3.0.0-bin-hadoop2.7 to c:\apps
Now set the following environment variables.
SPARK_HOME = C:\apps\spark-3.0.0-bin-hadoop2.7
HADOOP_HOME = C:\apps\spark-3.0.0-bin-hadoop2.7
PATH=%PATH%;C:\apps\spark-3.0.0-bin-hadoop2.7\bin
Setup winutils.exe
Download wunutils.exe file from winutils, and copy it to %SPARK_HOME%\bin folder. Winutils are different for each Hadoop version hence download the right version from https://github.com/steveloughran/winutils
spark-shell
Spark binary comes with interactive spark-shell. In order to start a shell, go to your SPARK_HOME/bin directory and type “spark-shell2“. This command loads the Spark and displays what version of Spark you are using.
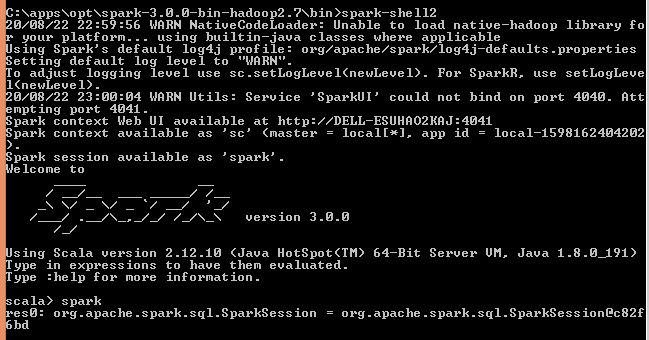
By default, spark-shell provides with spark (SparkSession) and sc (SparkContext) object’s to use. Let’s see some examples.
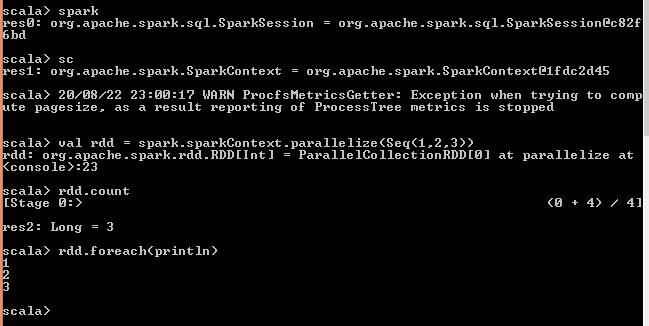
Spark-shell also creates a Spark context web UI and by default, it can access from http://localhost:4041.
spark-submit
The spark-submit command is a utility to run or submit a Spark or PySpark application program (or job) to the cluster by specifying options and configurations, the application you are submitting can be written in Scala, Java, or Python (PySpark) code. You can use this utility in order to do the following.
- Submitting Spark application on different cluster managers like Yarn, Kubernetes, Mesos, and Stand-alone.
- Submitting Spark application on client or cluster deployment modes
./bin/spark-submit \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key<=<value> \
--driver-memory <value>g \
--executor-memory <value>g \
--executor-cores <number of cores> \
--jars <comma separated dependencies>
--class <main-class> \
<application-jar> \
[application-arguments]
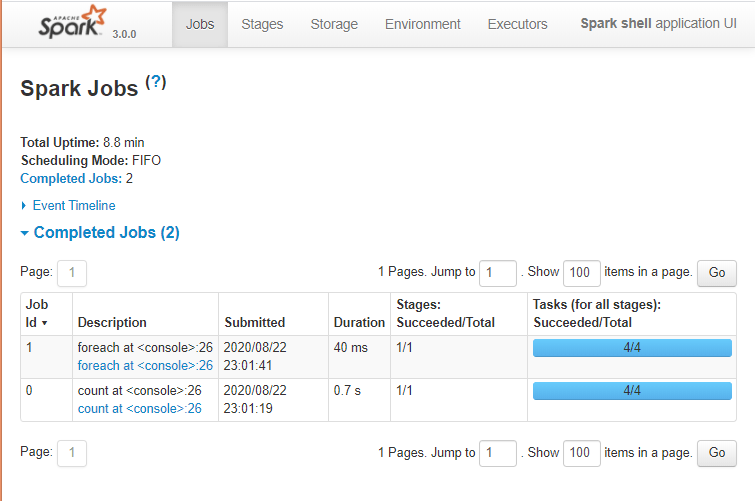
Spark Web UI
Apache Spark provides a suite of Web UIs (Jobs, Stages, Tasks, Storage, Environment, Executors, and SQL) to monitor the status of your Spark application, resource consumption of Spark cluster, and Spark configurations. On Spark Web UI, you can see how the operations are executed.
Spark History Server
Spark History server, keep a log of all completed Spark applications you submit by spark-submit, spark-shell. before you start, first you need to set the below config on spark-defaults.conf
spark.eventLog.enabled true
spark.history.fs.logDirectory file:///c:/logs/path
Now, start the spark history server on Linux or mac by running.
$SPARK_HOME/sbin/start-history-server.sh
If you are running Spark on windows, you can start the history server by starting the below command.
$SPARK_HOME/bin/spark-class.cmd org.apache.spark.deploy.history.HistoryServer
By default, History server listens at 18080 port and you can access it from a browser using http://localhost:18080/
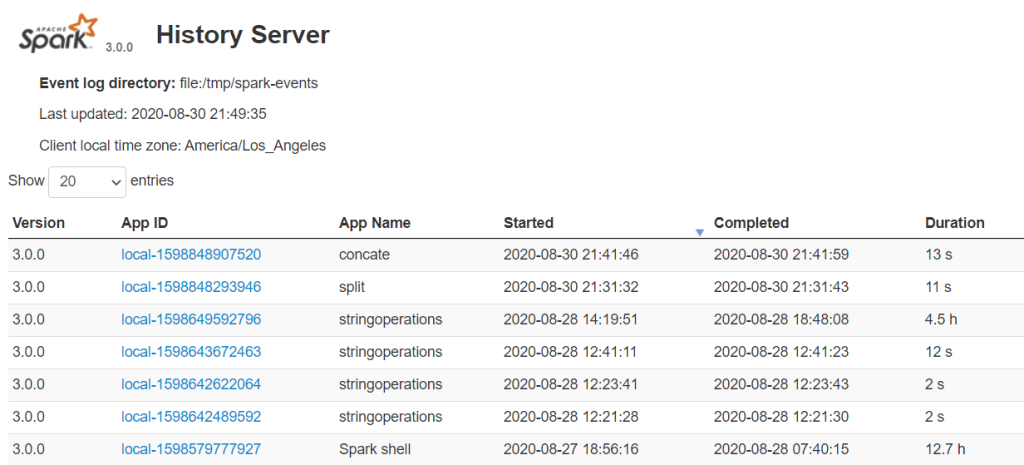
By clicking on each App ID, you will get the details of the application in Spark web UI.
The history server is very helpful when you are doing Spark performance tuning to improve spark jobs where you can cross-check the previous application run with the current run.
Spark Modules
- Spark Core
- Spark SQL
- Spark Streaming
- Spark MLlib
- Spark GraphX

Spark Core
In this section of the Apache Spark Tutorial, you will learn different concepts of the Spark Core library with examples in Scala code. Spark Core is the main base library of Spark which provides the abstraction of how distributed task dispatching, scheduling, basic I/O functionalities and etc.
Before getting your hands dirty on Spark programming, have your Development Environment Setup to run Spark Examples using IntelliJ IDEA
SparkSession
SparkSession introduced in version 2.0, It is an entry point to underlying Spark functionality in order to programmatically use Spark RDD, DataFrame and Dataset. It’s object spark is default available in spark-shell.
Creating a SparkSession instance would be the first statement you would write to program with RDD, DataFrame and Dataset. SparkSession will be created using SparkSession.builder() builder pattern.
import org.apache.spark.sql.SparkSession
val spark:SparkSession = SparkSession.builder()
.master("local[1]")
.appName("mytechmint.com")
.getOrCreate()
Spark Context
SparkContext is available since Spark 1.x (JavaSparkContext for Java) and is used to be an entry point to Spark and PySpark before introducing SparkSession in 2.0. Creating SparkContext was the first step to the program with RDD and to connect to Spark Cluster. It’s object sc by default available in spark-shell.
Since Spark 2.x version, When you create SparkSession, SparkContext object is by default create and it can be accessed using spark.sparkContext
Note that you can create just one SparkContext per JVM but can create many SparkSession objects.
Apache Spark RDD Tutorial
RDD (Resilient Distributed Dataset) is a fundamental data structure of Spark and it is the primary data abstraction in Apache Spark and the Spark Core. RDDs are fault-tolerant, immutable distributed collections of objects, which means once you create an RDD you cannot change it. Each dataset in RDD is divided into logical partitions, which can be computed on different nodes of the cluster.
This Apache Spark RDD Tutorial will help you start understanding and using Apache Spark RDD (Resilient Distributed Dataset) with Scala code examples. All RDD examples provided in this tutorial were also tested in our development environment and are available at GitHub spark scala examples project for quick reference.
In this section of the Apache Spark tutorial, I will introduce the RDD and explains how to create them and use their transformation and action operations. Here is the full article on Spark RDD in case if you wanted to learn more of and get your fundamentals strong.
RDD Creation
In order to create an RDD, first, you need to create a SparkSession which is an entry point to the PySpark application. SparkSession can be created using a builder() or newSession() methods of the SparkSession.
Spark session internally creates a sparkContext variable of SparkContext. You can create multiple SparkSession objects but only one SparkContext per JVM. In case if you want to create another new SparkContext you should stop existing Sparkcontext (using stop()) before creating a new one.
using parallelize()
SparkContext has several functions to use with RDDs. For example, it’s parallelize() method is used to create an RDD from a list.
using textFile()
RDD can also be created from a text file using textFile() function of the SparkContext.
Once you have an RDD, you can perform transformation and action operations. Any operation you perform on RDD runs in parallel.
RDD Operations
On PySpark RDD, you can perform two kinds of operations.
RDD transformations – Transformations are lazy operations. When you run a transformation(for example update), instead of updating a current RDD, these operations return another RDD.
RDD actions – operations that trigger computation and return RDD values to the driver.
RDD Transformations
Transformations on Spark RDD return another RDD and transformations are lazy meaning they don’t execute until you call an action on RDD. Some transformations on RDD’s are flatMap(), map(), reduceByKey(), filter(), sortByKey() and return new RDD instead of updating the current.
RDD Actions
RDD Action operation returns the values from an RDD to a driver node. In other words, any RDD function that returns non RDD[T] is considered as an action.
Some actions on RDDs are count(), collect(), first(), max(), reduce() and more.
Spark DataFrame
DataFrame definition is very well explained by Databricks hence I do not want to define it again and confuse you. Below is the definition I took it from Databricks.
DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as structured data files, tables in Hive, external databases, or existing RDDs.
– Databricks
If you are coming from a Python background I would assume you already know what Pandas DataFrame is; PySpark DataFrame is mostly similar to Pandas DataFrame with the exception PySpark DataFrames are distributed in the cluster (meaning the data in DataFrame’s are stored in different machines in a cluster) and any operations in PySpark executes in parallel on all machines whereas Panda Dataframe stores and operates on a single machine.
If you have no Python background, I would recommend you learn some basics on Python before you proceeding this Spark tutorial. For now, just know that data in PySpark DataFrame’s are stored in different machines in a cluster.
Is PySpark faster than Pandas?
Due to parallel execution on all cores on multiple machines, PySpark runs operations faster then pandas. In other words, pandas DataFrames run operations on a single node whereas PySpark runs on multiple machines. To know more read at pandas DataFrame vs PySpark Differences with Examples.
DataFrame Creation
The simplest way to create a DataFrame is from a Python list of data. DataFrame can also be created from an RDD and by reading files from several sources.
using createDataFrame()
By using createDataFrame() function of the SparkSession you can create a DataFrame.
Since DataFrame’s are structure format which contains names and columns, we can get the schema of the DataFrame using df.printSchema()
df.show() shows the 20 elements from the DataFrame.
DataFrame Operations
Like RDD, DataFrame also has operations like Transformations and Actions.
DataFrame from External Data Sources
In real-time applications, DataFrames are created from external sources like files from the local system, HDFS, S3 Azure, HBase, MySQL table e.t.c. Below is an example of how to read a CSV file from a local system.
Supported File Formats
DataFrame has a rich set of API which supports reading and writing several file formats
- csv
- text
- Avro
- Parquet
- tsv
- xml and many more
PySpark SQL
PySpark SQL is one of the most used PySpark modules which is used for processing structured columnar data format. Once you have a DataFrame created, you can interact with the data by using SQL syntax.
In other words, Spark SQL brings native RAW SQL queries on Spark meaning you can run traditional ANSI SQL’s on Spark Dataframe, in the later section of this PySpark SQL tutorial, you will learn in detail using SQL select, where, group by, join, union e.t.c
In order to use SQL, first, create a temporary table on DataFrame using createOrReplaceTempView() function. Once created, this table can be accessed throughout the SparkSession using sql() and it will be dropped along with your SparkContext termination.
Use sql() method of the SparkSession object to run the query and this method returns a new DataFrame.
Let’s see another PySpark example using group by.
This yields the below output
Similarly, you can run any traditional SQL queries on DataFrame’s using PySpark SQL.
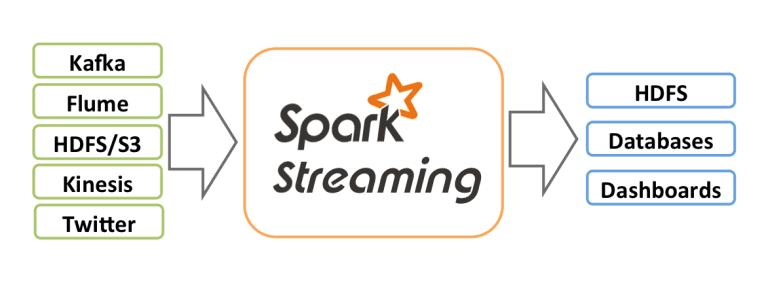
PySpark Streaming
PySpark Streaming is a scalable, high-throughput, fault-tolerant streaming processing system that supports both batch and streaming workloads. It is used to process real-time data from sources like file system folder, TCP socket, S3, Kafka, Flume, Twitter, and Amazon Kinesis to name a few. The processed data can be pushed to databases, Kafka, live dashboards etc.
Streaming from TCP Socket
Use readStream.format("socket") from Spark session object to read data from the socket and provide options host and port where you want to stream data from.
Spark reads the data from the socket and represents it in a “value” column of DataFrame. df.printSchema() outputs
After processing, you can stream the DataFrame to console. In real-time, we ideally stream it to either Kafka, database e.t.c
Streaming from Kafka
Using Spark Streaming we can read from Kafka topic and write to Kafka topic in TEXT, CSV, AVRO and JSON formats

Below PySpark example, writes a message to another topic in Kafka using writeStream()
PySpark MLlib
In this section, I will cover pyspark examples by using MLlib library.
PySpark GraphFrames
PySpark GraphFrames are introduced in Spark 3.0 version to support Graphs on DataFrame’s. Prior to 3.0, Spark has GraphX library which ideally runs on RDD and loses all Data Frame capabilities.
“GraphFrames is a package for Apache Spark which provides DataFrame-based Graphs. It provides high-level APIs in Scala, Java, and Python. It aims to provide both the functionality of GraphX and extended functionality taking advantage of Spark DataFrames. This extended functionality includes motif finding, DataFrame-based serialization, and highly expressive graph queries.” – GRAPHFRAMES.GITHUB.IO
Difference between GraphX and GraphFrame
GraphX works on RDDs whereas GraphFrames works with DataFrames.
Conclusion
PySpark is very vast and you can learn everything in a very simplified and easy way @mytechmint, Continue with the next PySpark tutorial and feel free to use the comment box in case you have any queries.

