Introduction to PySpark substring
PySpark substring is a function that is used to extract the substring from a DataFrame in PySpark. By the term substring, we mean to refer to a part of a portion of a string. We can provide the position and the length of the string and can extract the relative substring from that.
PySpark SubString returns the substring of the column in PySpark.
We can also extract a character from a String with the substring method in PySpark. All the required output from the substring is a subset of another String in a PySpark DataFrame. This function is used in PySpark to work deliberately with string type DataFrame and fetch the required needed pattern for the same.
PySpark substring Syntax
The syntax for the PySpark substring function is:-
df.columnName.substr(s,l)the column name is the name of the column in DataFrame where the operation needs to be done.
S:- The starting Index of the PySpark Application.
L:- The Length to which the Substring needs to be extracted.
Df:- The PySpark DataFrame.
b=a.withColumn(“Sub_Name”,a.Name.substr(1,3))
Screenshot:
![]()
The withColumn function is used in PySpark to introduce New Columns in Spark DataFrame.
a.Name is the name of column name used to work with the DataFrame String whose value needs to be fetched.
Working of PySpark substring Function
Let us see somehow the SubString function works in PySpark:-
The substring function is a String Class Method. The return type of substring is of the Type String that is basically a substring of the DataFrame string we are working on.
A certain Index is specified starting with the start index and end index, the substring is basically the subtraction of End – Start Index.
String basically is a char[] having the character of the String with an offset and count. A new string is created with the same char[] while calling the substring method. A different offset and count is created that basically is dependent on the input variable provided by us for that particular string DataFrame.
The count is the length of the string in which we are working for a given DataFrame.
By This method, the value of the String is extracted using the index and input value in PySpark.
One more method prior to handling memory leakage is the creation of new char[] every time the method is called and no more offset and count fields in the string.
Example of PySpark substring
Let us see some examples of how the PySpark SubString function works:-
Let’s start by creating a small DataFrame on which we want our DataFrame substring method to work.
a= spark.createDataFrame(["SAM","JOHN","AND","ROBIN","ANAND"], "string").toDF("Name")This creates a Data Frame and the type of data in DataFrame is of type String.
Let us see the first example to check how substring normal function works:-
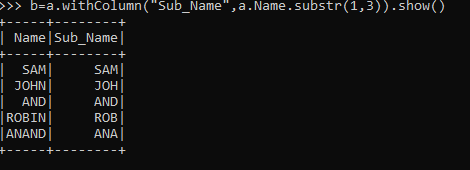
b=a.withColumn("Sub_Name",a.Name.substr(1,3)).show()This will create a New Column with the Name of Sub_Name with the SubStr
The output will only contain the substring in a new column from 1 to 3.
Screenshot:
Let’s check if we want to take the elements from the last index. The last index of a substring can be fetched by a (-) sign followed by the length of the String.
Let’s work with the same data frame as above and try to observe the scenario.
Creation of Data Frame.
a= spark.createDataFrame(["SAM","JOHN","AND","ROBIN","ANAND"], "string").toDF("Name")Let’s try to fetch a part of SubString from the last String Element.
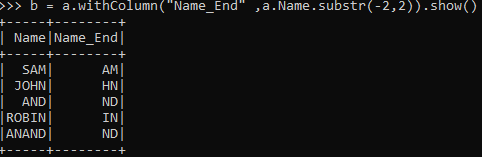
b = a.withColumn("Name_End" ,a.Name.substr(-2,2))This prints out the last two elements from the Python Data Frame.
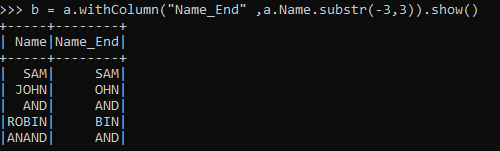
b = a.withColumn("Name_End" ,a.Name.substr(-3,3)).show()This will print the last 3 elements from the DataFrame.
Screenshot:
The substring can also be used to concatenate the two or more Substring from a Data Frame in PySpark and result in a new substring.
The way to do this with substring is to extract both the substrings from the desired length needed to extract and then use the String concat method on the same.
Let’s check an example for this by creating the same data Frame that was used in the previous example.
Creation of Data Frame.
a= spark.createDataFrame(["SAM","JOHN","AND","ROBIN","ANAND"], "string").toDF("Name")Now let’s try to concat two sub Strings and put that in a new column in a Python Data Frame.
Since SQL functions Concat or Lit is to be used for concatenation just we need to import a simple SQL function From PySpark.
from pyspark.sql.functions import concat, col, lit
This will all the necessary imports needed for concatenation.
b = a.withColumn("Concated_Value", concat(a.Name.substr(-3,3),lit("--"),a.Name.substr(1,3))).show()This will concatenate the last 3 values of a substring with the first 3 values and display the output in a new Column. If the string length is the same or smaller then all the string will be returned as the output.
Screenshot:
From these above examples, we saw how the substring methods are used in PySpark for various Data Related operations.

