Introduction to PySpark Logistic Regression
PySpark Logistic Regression is a type of supervised machine learning model which comes under the classification type. This algorithm defines the relationships among the data and classifies the data according to the relation among them. Logistic regression is the fundamental technique in classification that is relatively faster and easier to compute.
It is based on the training and testing of the data model in the machine learning model of PySpark. It predicts the probability of the dependent variable. It is a predictive analysis that describes the data and explains the relationship among the variable of that. In this article, we will try to analyze the various method used in Logistic Regression with the data in PySpark. Let us try to see about PySpark logistic regression in some more details
Syntax of PySpark Logistic Regression
The syntax for the PySpark Logistic Regression function is :
from pyspark.sql import Row
from pyspark.ml.classification import LogisticRegression
b = LogisticRegression(weightCol="weight").Import statement that is used.
LogisticRegression: The model used with the column name to be used on.
Output:

Working of Logistic Regression in Pyspark
Let us see somehow logistic regression operation works in PySpark.
- It is a classification algorithm that predicts the dependency of the data variable. The logistic regression predicts the binary outcome where only two scenarios happen up to one that it is present either a yes or no it is not present.
- It works on some assumptions of the dependent and independent variable that is used. These assumptions are then used for training purposes. As the independent variables must be independent of each other, the size of the data must be powerful and strong. The independent variables come under those variables which can influence the result further.
- There are several types of Logistic Regression that include the Binary regression which predicts the relationship between dependent and independent variables.
- Then we can have the Multinomial regression which can have two or more discrete outcomes.
- The PySpark data frame has columns containing labels, features , and the column name that needs to be used for the regression model technique calculation.
- Let’s check the creation and working of the logistic regression function with some coding examples.
Examples of PySpark Logistic Regression
Let us see some examples of PySpark Logistic Regression.
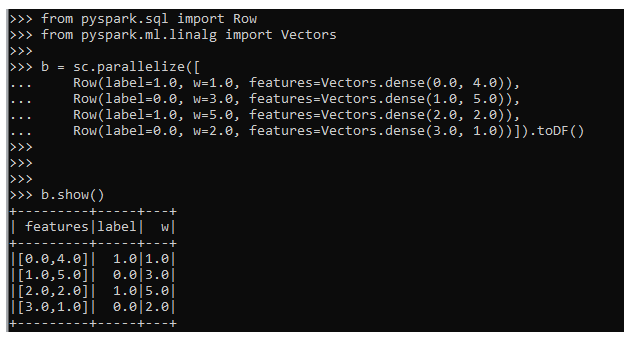
Let’s start by creating a simple data frame in PySpark on which we can use the model. We will be using the sc. Parallelize method to create the data frame followed by the toDF method in PySpark which contains the data needed for creating the Regression model.
The necessary imports are used to create the features and Row in PySpark.
from pyspark.sql import Row
from pyspark.ml.linalg import Vectors
b = sc.parallelize([
Row(label=1.0, w=1.0, features=Vectors.dense(0.0, 4.0)),
Row(label=0.0, w=3.0, features=Vectors.dense(1.0, 5.0)),
Row(label=1.0, w=5.0, features=Vectors.dense(2.0, 2.0)),
Row(label=0.0, w=2.0, features=Vectors.dense(3.0, 1.0))]).toDF()
b.show()Output:
We can import the Logistic Regression model to classify and start the operation over the data frame
from pyspark.ml.classification import LogisticRegression
This applies over the column of the PySpark dataframe.
c = LogisticRegression(weightCol="w")Output:

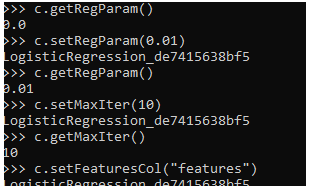
Now let’s try to analyze some of the methods that are used in the Logistic Regression model.
1:- To get the regParam or its default value.
c.getRegParam()2:- To set the regParam by the regression function.
c.setRegParam(0.01)3:- To get the updated value.
c.getRegParam()4:- To set the MaxIter by the regression function
c.setMaxIter(10)5:- To get the updated value of the iterator.
c.getMaxIter()
c.setFeaturesCol("features")These are the Logistics Regression models that are used with the PySpark data frame model and results can be evaluated back from the model. Note the model cannot be used for the continuous data and the accuracy can vary if the data size of the model is small. The model is comparatively faster and the most trusted and renowned used model for prediction.
Output:
Note
- PySpark Logistic Regression is a Machine learning model used for data analysis.
- PySpark Logistic Regression is a classification that predicts the dependency of data over each other in the PySpark ML model.
- PySpark Logistic Regression is a faster way of classification of data and works fine with larger data set with accurate results.
- PySpark Logistic Regression is well used with discrete data where data is uniformly separated.
- PySpark Logistic Regression uses the dependent and independent variable model for analysis.

