Introduction to PySpark Lag
PySpark lag is a function in PySpark that works as the offset row returning the value of the before row of a column with respect to the current row in PySpark. This is an operation in PySpark that returns the row just before the current row. The return value is the column name that is the offset just before the current record. If the value is less the return type is null here.
This lag function is used in PySpark for various column-level operations where the previous data needs in the column for data processing. This PySpark “lag” is a Window function of PySpark that is used widely in table and SQL level architecture of the PySpark data model.
In this article, we will try to analyze the various ways of using the LAG operation PySpark. Let us try to see about PYSPARK LAG in some more details.
The syntax for PySpark Lag
The syntax for PySpark lag function is:
windowSpec = Window.partitionBy("Name").orderBy("Add")
c = b.withColumn("lag",lag("ID",1).over(windowSpec)).show()- b:- The data frame used.
- Withcolumn:- Introduces the new column named Lag.
- Lag:- The function to be used with the integer value over it.
- Over:- The partition and order by the function used.
- WindowSpec:- The Window operation to be used.
Screenshot:
![]()
Working of Lag in PySpark
The LAG function in PySpark allows the user to query on more than one row of a table returning the previous row in the table. The function uses the offset value that compares the data to be used from the current row and the result is then returned if the value is true.
An offset given the value as 1 will check for the row value over the data frame and will return the previous row at any given time in the partition.
This takes up the parameter as the column name and the offset value that works over the LAG function in PySpark.
The benefit of having the LAG function is the same row result is fetched with the use of self-join in PySpark and the current value is compared with the previous values needed.
The default return type is also used that specifies the value to be returned. If the data is partitioned by a certain column value the LAG function is used over those values as well as if it is not the whole data frame is considered as one partition.
Let’s check the creation and working of the LAG method with some coding examples.
Examples of PySpark Lag
Let us see some examples of how the PySpark lag operation works.
Let’s start by creating simple data in PySpark.
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)Created Data Frame using Spark.createDataFrame.
Screenshot:

Let us check for the important update that needs to be done. The Window operation is used for the Windows operation.
from pyspark.sql.window import Window
from pyspark.sql.functions import row_numberThis is used to partition the data based on column and the order by is also used for ordering the data frame.
windowSpec = Window.partitionBy("Name").orderBy("Add")Let us use the lag function over the Column name over the windowspec function.
This adds up the new Column value over the column name the offset value is given.
c = b.withColumn("lag",lag("ID",1).over(windowSpec)).show()This takes the data of the previous one, The data is introduced into a new Column with the new column name. This checks the data and offset value and compares it, null is returned if the value is smaller or the offset value is less than the current row.
Output:
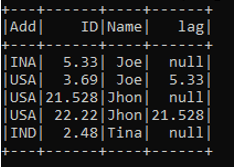
The offset value is checked that compares the data and column value is returned.
If 1 is used as the offset it will return the ID that is 1 position lower in the result.
If 2 is used as the offset value the return value will be the ID that will be 2 ID lower. The return type is null as it is not able to find the values corresponding to the offset in the LAG function.
>>> c = b.withColumn("lag",lag("ID",2).over(windowSpec)).show()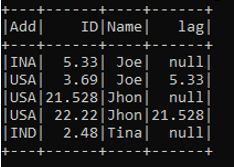
Note:
1. PySpark lag is a Window operation in PySpark.
2. PySpark lag takes the offset of the previous data from the current one.
3. PySpark lag returns null if the condition is not satisfied. i.e if there are fewer than offset rows before the current row.
4. PySpark lag needs the aggregation of data to be done over the PySpark data frame.

