Introduction to PySpark Coalesce
PySpark Coalesce is a function in PySpark that is used to work with the partition data in a PySpark Data Frame. The Coalesce method is used to decrease the number of partitions in a Data Frame; The coalesce function avoids the full shuffling of data. It adjusts the existing partition that results in a decrease of partition. The method reduces the partition number of a data frame.
This is a much more optimized version where the movement of data is on the lower side. This comparatively makes it faster in the PySpark Data Frame model. This article will try to analyze the coalesce function in details with examples and try to understand how it works with PySpark Data Frame.
Syntax of PySpark Coalesce
The syntax for the PySpark Coalesce function is:
b = a.coalesce(5)- a: The PySpark RDD.
- Coalesce: The Coalesce function to work on a partition.
Screenshot:
![]()
Working of PySpark Coalesce
The Coalesce function reduces the number of partitions in the PySpark Data Frame. By reducing it avoids the full shuffle of data and shuffles the data using the hash partitioner; this is the default shuffling mechanism used for shuffling the data. It avoids the full shuffle where the executors can keep data safely on the minimum partitions. This only moves the data off from the extra node. This uses the existing partitions that minimize the data shuffle. The amount of data in each partition can be evenly different. Coalesce using the existing transaction that makes it faster for data shuffling. The Coalesce creates a new RDD every time, keeping track of previous shuffling over the older RDD. Coalesce works with data with lots of partitions where which combines it down and produces a new RDD with lesser partition avoiding the data shuffling and minimum movement over the network.
Examples of PySpark Coalesce
Let us see some examples of PySpark Coalesce:
Let’s start by creating a simple RDD over which we want to understand the Coalesce operation.
Creation of RDD:
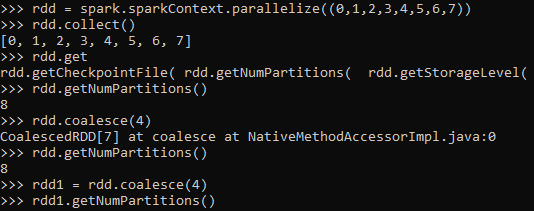
rdd = spark.sparkContext.parallelize((0,1,2,3,4,5,6,7))
rdd.collect()
[0, 1, 2, 3, 4, 5, 6, 7]Screenshot:

Let’s check the partition that has been created while creation of RDD. This can be done using the getNumpartitions(), this checks for the number of partitions that have been used for creating the RDD.
rdd.getNumPartitions()
Screenshot:
![]()
We will start by using the coalesce function over the given RDD.
rdd1 = rdd.coalesce(4)CoalescedRDD[7] at coalesce at NativeMethodAccessorImpl.java:0
This RDD is partitioned and decreased to 4.
rdd1.getNumPartitions()The result shows the partition to be decreased by the amount of parameters given.
Screenshot:
Let’s try to understand more precisely by creating a data Frame and using the coalesce function on it.
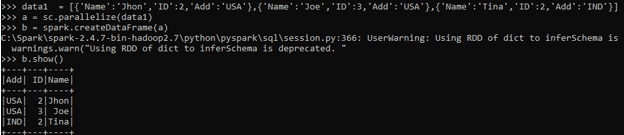
data1 = [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'USA'},{'Name':'Tina','ID':2,'Add':'IND'}]A sample data is created with Name, ID and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created DataFrame using Spark.createDataFrame.
Screenshot:
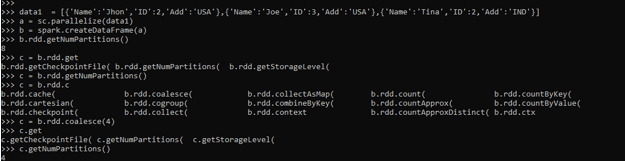
The Data frame coalesce can be used in the same way by using the.RDD that converts it to RDD and getting the NUM Partitions.
b.rdd.getNumPartitions()
c = b.rdd.coalesce(4)
c.getNumPartitions()Let us check some more examples for Coalesce function.
ScreenShot:
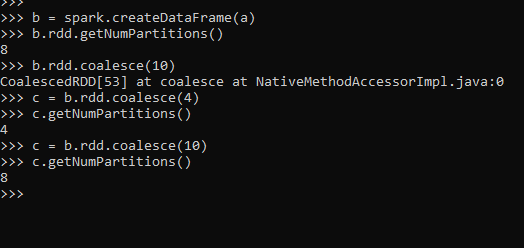
Let us try to increase the partition using the coalesce function; we will try to increase the partition from the default partition.
b = spark.createDataFrame(a)
b.rdd.getNumPartitions()Here the Default NUM partition is 8. Let try to increase the partition with the coalesce function.
c = b.rdd.coalesce(10)
c.getNumPartitions()Here we can see that by trying to increase the partition, the default remains the same. So coalesce can only be used to reduce the number of the partition.
Screenshot:
Let us check some more example of PySpark Coalesce:
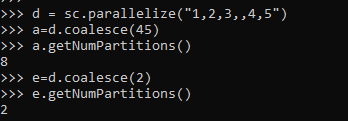
d = sc.parallelize("1,2,3,,4,5")
a=d.coalesce(45)
a.getNumPartitions()
e=d.coalesce(2)
e.getNumPartitions()Screenshot :
These are some of the Examples of Coalesce Function in PySpark.
Note:
1. Coalesce Function works on the existing partition and avoids full shuffle.
2. It is optimized and memory efficient.
3. It is only used to reduce the number of the partition.
4. The data is not evenly distributed in Coalesce.
5. The existing partition are shuffled in Coalesce.

