Introduction to PySpark Read Parquet
PySpark read.parquet is a method provided in PySpark to read the data from parquet files, make the Data Frame out of it, and perform Spark-based operation over it. Parquet is an open-source file format designed for the storage of Data on a columnar basis; it maintains the schema along with the Data making the data more structured to be read and process.
PySpark comes with the function read.parquet used to read these types of parquet files from the given file location and work over the Data by creating a Data Frame out of it. This parquet file’s location can be anything starting from a local File System to a cloud-based storage structure.
Syntax for PySpark Read Parquet
The syntax for the READ PARQUET function is:-
spark.read.parquet(“path of the parquet file”)Spark:- The Spark Session.
Read.parquet:- The spark function used to read the parquet File.
Argument:- The Path of the parquet File.
spark.re
spark.read.parquet(“/ / / / / /”)Screenshot:-
![]()
Working of PySpark Read Parquet
A parquet format is a columnar way of data processing in PySpark, that data is stored in a structured way. PySpark comes up with the functionality of spark.read.parquet that is used to read these parquet-based data over the spark application. Data Frame or Data Set is made out of the Parquet File, and spark processing is achieved by the same.
Parquet File format is good to process big data as we have the option to filter those data, which is only of use for data processing. It supports compression and various encoding scheme making it efficient for Spark Processing.
PySpark automatically captures the schema of the original data reducing the storage by 75 percent of the data.
While reading the parquet file, the columns are automatically converted to nullable. The parquet file source is able to discover the partitioning used and the information about the same automatically. This partitioning is used to store and process data. By processing the file with the spark.read.parquet, the Spark SQL automatically extracts the information, and the schema is returned. The Data Type is inferred automatically.
The schema can be merged by enabling the mergeSchema to True while reading the parquet File.
The is how we can read the Parquet file in PySpark.
Example of PySpark Read Parquet
Let us see some examples of how the PySpark read parquet function works:-
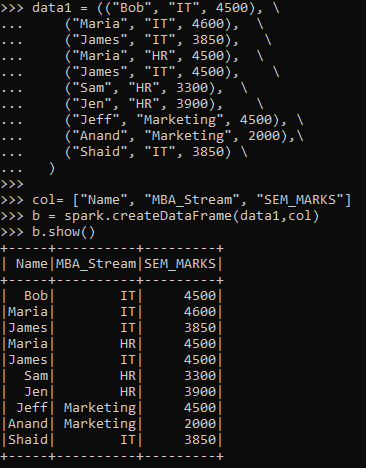
Let’s start by creating a PySpark Data Frame. A data frame of students with the concerned Dept. and overall semester marks are taken for consideration, and a data frame is made upon that.
Code:
data1 = (("Bob", "IT", 4500), \
("Maria", "IT", 4600), \
("James", "IT", 3850), \
("Maria", "HR", 4500), \
("James", "IT", 4500), \
("Sam", "HR", 3300), \
("Jen", "HR", 3900), \
("Jeff", "Marketing", 4500), \
("Anand", "Marketing", 2000),\
("Shaid", "IT", 3850) \
)
col= ["Name", "MBA_Stream", "SEM_MARKS"] b = spark.createDataFrame(data1,col)The create data to create the Data Frame from the column and Data
b.printSchema()Screenshot:
Since we don’t have any parquet file with us, we will try first to write a parquet file to a location and then try to read that using the spark.read.parquet.
We have a data frame; let’s write the data frame in parquet format.
b.write.parquet(“location”)The file will be written up to a given location.
We can access this parquet file using the
Spark. Read.parquet(“location”)We can store a parquet file in a data Frame and can perform operation overs it.
The DataFrame.show() can show the parquet data within.
dataframe.show()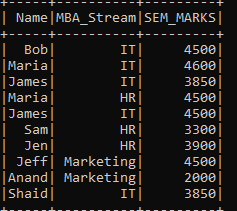
We can also have different modes that can be used to append or overwrite a given parquet file location.
We can also create a temp table while reading the parquet file and then perform the SQL-related operations.
A partition can also be made on the parquet file that can be used while reading the parquet file. The Folders are made for each partition, and we can read the data from the specified folder in that parquet Location. The same partitioned table can also be from that data.
From the above example, we saw the use of read.parquet function with PySpark.

