Introduction to PySpark groupBy Function
PySpark GROUPBY is a function in PySpark that allows to group rows together based on some columnar value in spark application. The group By function is used to group Data based on some conditions and the final aggregated data is shown as the result. In simple words if we try to understand what exactly group by does in PySpark is simply grouping the rows in a spark Data Frame having some values which can be further aggregated to some given result set.
The identical data are arranged in groups and the data is shuffled accordingly based on partition and condition. Advance aggregation of Data over multiple column is also supported by PySpark groupBy . Post performing Group By over a Data Frame the return type is a Relational Grouped Data set object that contains the aggregated function from which we can aggregate the Data.
Syntax For PySpark groupBy Function
The syntax for PySpark groupBy function is :-
df.groupBy(‘columnName’).max().show()
df :- The PySpark DataFrame
ColumnName :- The ColumnName for which the GroupBy Operations needs to be done.
Max() – A Sample Aggregate Function
a.groupBy(“Name”).max().show()Screenshot:-
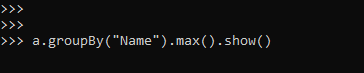
Working Of PySpark groupBy Function
Let us see somehow the groupBy function works in PySpark:-
The groupBy function is used to group data together based on same key value that operates on RDD / Data Frame in a PySpark application.
The data having the same key are shuffled together and is brought at a place that can grouped together. The shuffling happens over the entire network and this makes the operation a bit costlier one.
The one with same key is clubbed together and the value is returned based on the condition.
GroupBy statement is often used with aggregate function such as count , max , min ,avg that groups the result set then.
Group By can be used to Group Multiple columns together with multiple column name. Group By returns a single row for each combination that is grouped together and aggregate function is used to compute the value from the grouped data.
Example of groupByFunction in PySpark
Let us see some Example how PySpark groupBy function works :-
Let’s start by creating a simple Data Frame over we want to use the Filter Operation.
Creation of DataFrame:-
a= spark.createDataFrame(["SAM","JOHN","AND","ROBIN","ANAND"], "string").toDF("Name")Lets start with a simple groupBy code that filters the name in Data Frame.
a.groupby("Name").avg().show()This will Group the element with the name. The element with same key are grouped together and result is displayed .
Post aggregation function the data can be displayed.
Screenshot:-
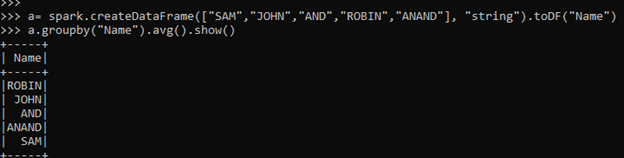
Lets try to understand more precisely by creating a data Frame with one than one column and using aggregate function in that.
data1 = [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'USA'},{'Name':'Tina','ID':2,'Add':'IND'}]A sample data is created with Name , ID and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)Created DataFrame using Spark.createDataFrame.
b.groupBy("Add").max().show()An Aggregation function max is used that takes the maximum post grouping the data.
The Maximum will be displayed as the output.
Screenshot:-
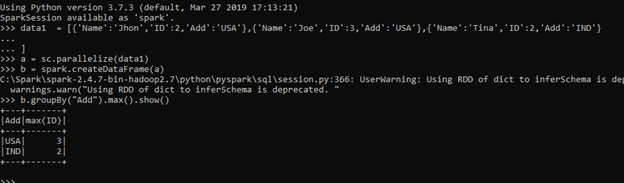
Suppose we want to take the sum of function that are grouped together.
For that we will use the aggregation function sum () to sum the id over that.
b.groupBy("Add").sum().show()This will group the data and Sum it.
Output:-
ScreenShot:-
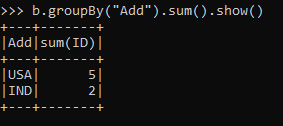
The same can be used by agg function that will aggregate the data post grouping the Data Frame.
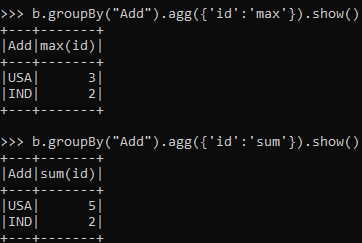
b.groupBy("Add").agg({'id':'max'}).show()Output:-
The output will have the same result giving the maximum ID.
The same can be applied with the Sum operation also.
b.groupBy("Add").agg({'id':'sum'}).show()This is the same as the result obtained.
Screenshot:-
Let’s checkout some more aggregation functions using groupBy.
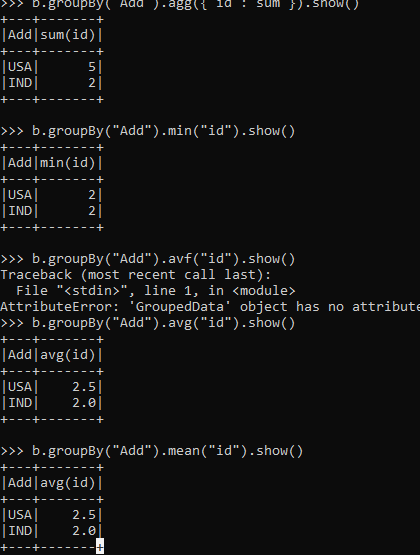
To Fetch the minimum Data.
b.groupBy("Add").min("id").show()Output:-
To get the average .
b.groupBy("Add").avg("id").show()To get the mean of the Data.
b.groupBy("Add").mean("id").show()Screenshot:-
These are some of the Examples of GroupBy Function in PySpark.

