Introduction to PySpark Count Distinct
PySpark count distinct is a function used in PySpark that are basically used to count the distinct number of element in a PySpark Data frame, RDD. The meaning of distinct as it implements is Unique. So we can find the count of a number of unique records present in a PySpark Data Frame using this function.
The distinct function helps in avoiding duplicates of the data making the data analysis easier. The supporting count function finds out the way to count the number of distinct elements present in the PySpark Data Frame, making it easier to rectify and work. This is an important function in Data Analysis with PySpark as the duplicate data is not accepted much in Analytics.
Syntax PySpark Count Distinct
The syntax for the function is:-
b.distinct().count()- b: The PySpark Data Frame used.
- distinct(): The distinct function used to filter duplicate values.
- dount(): Count operation to be used.
Screenshot:
![]()
Working of Count Distinct in Pyspark
The distinct function takes up the existing PySpark Data Frame and returns a new Data Frame. This new data removes all the duplicate records; post removal of duplicate data, the count function is used to count the number of records present. The count is an action that initiates the driver execution and returns data back to the driver. This counts up the data present and counted data is returned back. Distinct uses the hash Code, and the equals method for the object determination and the count operation is used to count the items out of it. The removal of duplicate items from the Data Frame makes the data clean with no duplicates.
Examples of PySpark Count Distinct
Let us see some Examples of how the PySpark DISTINCT COUNT function works:-
Let’s start by creating simple data in PySpark.
data1 = [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'USA'},{'Name':'Tina','ID':2,'Add':'IND'},{'Name':'Jhon','ID':2, 'Add':'USA'},{'Name':'Joe','ID':5,'Add':'INA'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Screenshot:
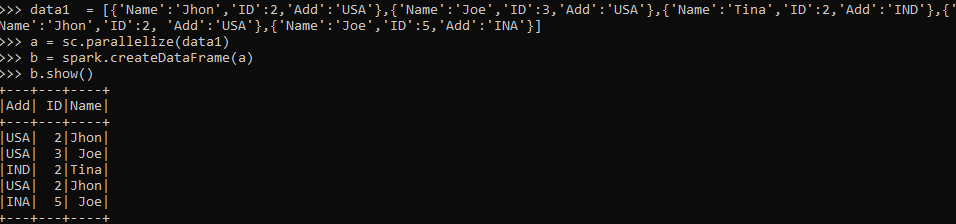
This data frame contains the duplicate value that can be removed using the distinct function.
Code:
b.distinct().show()Let’s try to count the number of data frames present using the count() method operation over the Data Frame.
b.distinct().count()This counts up the number of distinct elements in the Data Frame.
b.count()As we can see, the distinct count is lesser than the count the Data Frame was having, so the new data Frame has removed duplicates from the existing Data Frame and the count operation helps on counting the number.
Screenshot:
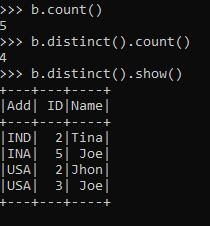
The distinct works on every element needed for comparison i.e all the elements should be common or equal. Only that a particular element will be called distinct and can be used with the distinct operation.
We can also check the distinct columns on a data Frame for a particular column using the countDistinct SQL function. The countDistinct function is a PySpark SQL function that is used to return the number of distinct elements in a group.
Let’s check that with an Example:
data1 = [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'USA'},{'Name':'Tina','ID':2,'Add':'IND'},{'Name':'Jhon','ID':2, 'Add':'USA'},{'Name':'Joe','ID':5,'Add':'INA'}] a = sc.parallelize(data1)
b = spark.createDataFrame(a)from pyspark.sql.functions import countDistinct
c = b.select(countDistinct("ID","Name")The count Distinct function is used to select the distinct column over the Data Frame. The above code returns the Distinct ID and Name elements in a Data Frame.
c = b.select(countDistinct("ID","Name")).show()ScreenShot:
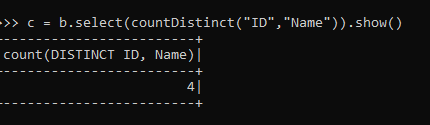
The same can be done with all the columns or single columns also.
c = b.select(countDistinct("ID")).show()There is 3 unique ID regarding the same so the distinct count return Value is 3.
ScreenShot:
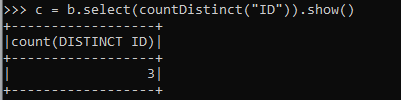
If we add all the columns and try to check for the distinct count, the distinct count function will return the same value as encountered above.
So the function:
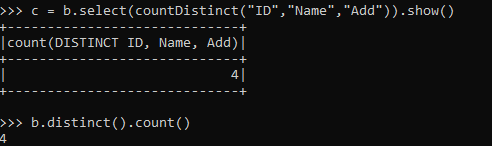
c = b.select(countDistinct("ID","Name","Add")).show()The result will be the same as the one with a distinct count function.
b.distinct().count()ScreenShot:
These are some of the Examples of DISTINCT COUNT Function in PySpark.
Note:
- Distinct Count is used to removing the duplicate element from the PySpark Data Frame.
- The count can be used to count existing elements.
- It creates a new data Frame with distinct elements in it.
- The Data doesn’t contain any duplicate value, and redundant data are not available.
- We can use the function over selected columns also in a PySpark Data Frame.
- The countDistinct() PySpark SQL function is used to work with selected columns in the Data Frame.

