Introduction to PySpark StructType
PySpark StructType is a class import that is used to define the structure for the creation of the data frame. The StructType provides the method of creation of data frame in PySpark. It is a collection or list of Struct Field Objects.
The StructType has the schema of the data frame to be defined, it contains the object that defines the name of the column, The type of the column, and the flag for each data frame. It has a struct Field inside which the column structure is defined in PySpark. It is a built-in data type that is a collection of Struct Field in the PySpark data frame.
In this article, we will try to analyze the various method used for StructType in PySpark.
Let us try to see about PySpark StructType in some more detail.
Syntax for PySpark StructType
The syntax for PySpark StructType function is:
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
sch = StructType([StructField("Name",StringType(),True),StructField("ID",StringType(), True),StructField("ADD",StringType() , True)])• sch: The Schema defined for the Data Frame to be created.
• StructType: The StructType Class.
• StructField: The schema can be defined with Struct Field.
Screenshot:

Working of StructType in Python
Let us see somehow StructType operation works in PySpark:
The StructType is used to define a schema of a data frame in PySpark. It is a built-in data type that is used to create a data frame in PySpark. The StructType itself has <struct> in the query plan, it is a Sequence of type Struct Field. Seq[StructField]. We can define the Column schema name with the parameters with Struct Field.
The first parameter includes the Name of the column, The Second being the Data Type to be used and the last being the Boolean flag for the data frame. It is used in the Query Plan in PySpark for the creation of a data frame. The creation of a new column can be done by adding a new Struct Field to the StructType. We can add the column that is resolved at the query planning phase while the creation of PySpark Data Frame.
Let’s check the creation and working of the StructType method with some coding examples.
Examples of PySpark StructType
Let us see some examples of how the PySpark StructType operation works:
Let’s start by creating simple data in PySpark.
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)Created Data Frame using Spark.createDataFrame.
Screenshot:
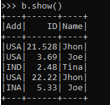
This creates the data frame with the column name as Name, Add, and ID. Now let us try to create the schema with the StructType.
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StructField, StringType, IntegerTypeThe import statement to be used for defining the Structtype and Struct Field.
sch = StructType([StructField("Name",StringType(),True),StructField("ID",StringType(), True),StructField("ADD",StringType() , True)])The StructType class and the Struct Field contain the name of the column, the data type of the column used, and the Boolean value for null values.
Let’s fill the data and create the data from the data frame using the StructType.
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'}
b = spark.createDataFrame(data1,sch)
b.show()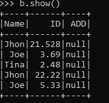
b.printSchema()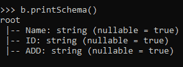
This creates a data frame in PySpark using the StructType.
We can also create a Nested Structtype object that contains the nested columns. Let us create the same with a coding example.
The nested schema contains elements inside the schema element.
nes_Sch = StructType([StructField("Name",StructType([StructField("f_name",StringType(), True),StructField("l_name",StringType() , True)])),StructField("ID",StringType(),True),StructField("Add",StringType() , True)])
data1 = [(("John","cena"),"123","UK"),(("Singh","dd"),"234","IND")] b = spark.createDataFrame(data1,nes_Sch)
b.show()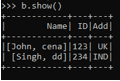
>> b.printSchema()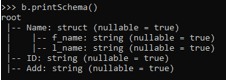
This shows how the nested schema is prepared using the Structtype as the Type of that Schema.
These are some of the Examples of PySpark StructType in PySpark.
Note:
- PySpark StructType is a way of creating a data frame in PySpark.
- PySpark StructType contains a list of Struct Field that has the structure defined for the data frame.
- PySpark StructType removes the dependency from spark code.
- PySpark StructType returns the schema for the data frame.
- PySpark StructType has the structure of data that can be done at run time as well as compile time.

