Introduction to PySpark Broadcast Join
PySpark Broadcast Join is a type of join operation in PySpark that is used to join data frames by broadcasting it in the PySpark application. This join can be used for the data frame that is smaller in size which can be broadcasted with the PySpark application to be used further.
It is a join operation of a large data frame with a smaller data frame in the PySpark Join model. It reduces the data shuffling by broadcasting the smaller data frame in the nodes of the PySpark cluster. The data is sent and broadcasted to all nodes in the cluster. This is an optimal and cost-efficient join model that can be used in the PySpark application.
In this article, we will try to analyze the various ways of using the BROADCAST JOIN operation PySpark.
Let us try to see about PySpark Broadcast Join in some more details.
Syntax of PySpark Broadcast Join
The syntax for the PySpark Broadcast Join function is:
d = b1.join(broadcast(b))- d: The final Data frame.
- B1: The first data frame to be used for join.
- B: The second broadcasted Data frame.
- Join:- The join operation is used for joining.
- Broadcast: Keyword to broadcast the data frame.
The parameter used by the like function is the character on which we want to filter the data.
Screenshot:
![]()
Working of PySpark Broadcast Join
Broadcasting is something that publishes the data to all the nodes of a cluster in the PySpark data frame. Broadcasting further avoids the shuffling of data and the data network operation is comparatively lesser.
The broadcast join operation is achieved by the smaller data frame with the bigger data frame model where the smaller data frame is broadcasted and the join operation is performed.
The smaller data is first broadcasted to all the executors in PySpark and then join criteria is evaluated, it makes the join fast as the data movement is minimal while doing the broadcast join operation.
The broadcast method is imported from the PySpark SQL function can be used for broadcasting the data frame to it.
Let’s check the creation and working of the Broadcast Join method with some coding examples.
Examples of PySpark Broadcast Join
Let us see some examples of how the PySpark Broadcast Join operation works:
Let’s start by creating simple data in PySpark.
data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}]A sample data is created with Name, ID, and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Screenshot:

Let us create the other data frame with data2. This data frame created can be used to broadcast the value and then join operation can be used over it.
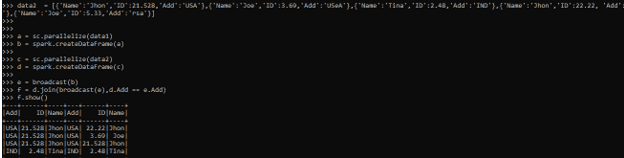
data2 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USeA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USdA'},{'Name':'Joe','ID':5.33,'Add':'rsa'}] c = sc.parallelize(data2)
d = spark.createDataFrame(c)Let us try to broadcast the data in the data frame, the method broadcast is used to broadcast the data frame out of it.
e = broadcast(b)Let us now join both the data frame using a particular column name out of it. This avoids the data shuffling throughout the network in the PySpark application.
f = d.join(broadcast(e),d.Add == e.Add)The condition is checked and then the join operation is performed on it.
Let us
f.show()Screenshot:
Let us try to understand the physical plan out of it.
f.explain()== Physical Plan ==
*(2) BroadcastHashJoin [Add#133], [Add#127], Inner, BuildRight
:- *(2) Filter isnotnull(Add#133)
: +- Scan ExistingRDD[Add#133,ID#134,Name#135] +- BroadcastExchange HashedRelationBroadcastMode(List(input[0, string, false]))
+- *(1) Filter isnotnull(Add#127)
+- Scan ExistingRDD[Add#127,ID#128,Name#129]Screenshot:

We can also do the join operation over the other columns also that can be further used for the creation of a new data frame.
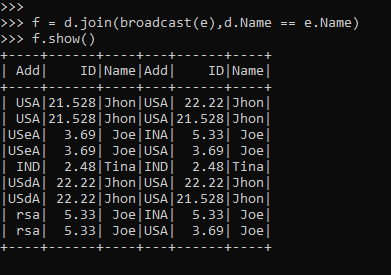
f = d.join(broadcast(e),d.Name == e.Name)
f.show()Screenshot:
Note:
1. PySpark Broadcast Join can be used for joining the PySpark data frame one with smaller data and the other with the bigger one.
2. PySpark Broadcast Join avoids the data shuffling over the drivers.
3. PySpark Broadcast Join is a cost-efficient model that can be used.
4. PySpark Broadcast Join is faster than shuffle join.

