Introduction to PySpark Filter
PySpark Filter is a function in PySpark added to deal with the filtered data when needed in a Spark Data Frame. Data Cleansing is a very important task while handling data in PySpark and PySpark Filter comes with the functionalities that can be achieved by the same. PySpark Filter is applied with the Data Frame and is used to Filter Data all along so that the needed data is left for processing and the rest data is not used. This helps in Faster processing of data as the unwanted or the Bad Data are cleansed by the use of filter operation in a Data Frame.
PySpark Filter condition is applied on Data Frame with several conditions that filter data based on Data, The condition can be over a single condition to multiple conditions using the SQL function. The Rows are filtered from RDD / Data Frame and the result is used for further processing.
Syntax of PySpark Filter
The syntax for PySpark Filter function is:
df.filter(#condition)- df: The PySpark DataFrame
- Condition: The Filter condition which we want to Implement on.
Screenshot:
![]()
Working of PySpark Filter
Let us see somehow the FILTER function works in PySpark:-
The Filter function takes out the data from a Data Frame based on the condition.
The condition is evaluated first that is defined inside the function and then the Row that contains the data which satisfies the condition is returned and the row failing that aren’t. The filter function first checks for all the rows over a condition by checking the columns and the condition written inside and evaluating each based on the result needed.
The filter condition is similar to where condition in SQL where it filters data based on the condition provided.
Example of PySpark Filter
Let us see some Examples of how the PySpark Filter function works:
Let’s start by creating a simple Data Frame over we want to use the Filter Operation.
Creation of DataFrame:
a= spark.createDataFrame(["SAM","JOHN","AND","ROBIN","ANAND"], "string").toDF("Name")Let’s start with a simple filter code that filters the name in Data Frame.
a.filter(a.Name == "SAM").show()This is applied to Spark DataFrame and filters the Data having the Name as SAM in it.
The output will return a Data Frame with the satisfying Data in it.
The same data can be filtered out and we can put the condition over the data whatever needed for processing.
a.filter(a.Name == "JOHN").show()This prints the DataFrame with the name JOHN with the filter condition.
Here we are using the method of DataFrame. Column method as the way to Filter and Fetch Data.
Another method that can be used to fetch the column data can be by using the simple SQL column method in PySpark SQL.
This can be done by importing the SQL function and using the col function in it.
from pyspark.sql.functions import col
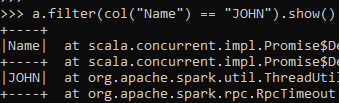
a.filter(col("Name") == "JOHN").show()This will filter the DataFrame and produce the same result as we got with the above example.
John is filtered and the result is displayed back.
Output:
Screenshot:
The same can be done if we try that with the SQL approach. Just need to pass the condition inside the filter condition the same way we pass it with SQL statement.
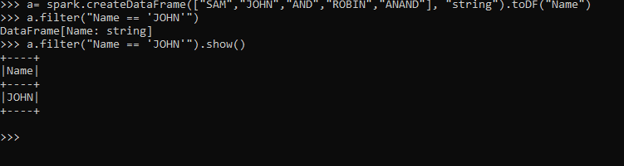
a.filter("Name == 'JOHN'")By this way, we can directly put a statement that will be the conditional statement for Data Frame and will produce the same Output.
a.filter("Name == 'JOHN'").show()ScreenShot:
We can also use multiple operators to filter data with PySpark DataFrame and filter data accordingly.
AND and OR operators can also be used to filter data there.
Let us check that with an example by creating a data frame with multiple columns.
data1= [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'MX'},{'Name':'Tina','ID':4,'Add':'IND'}] rd1 = sc.parallelize(data1)
df1 = spark.createDataFrame(rd1)This creates a DataFrame named DF1 with multiple columns as Name, Add, and ID.
Now let’s see the use of Filter Operation over multiple columns.
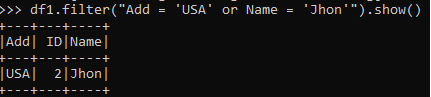
df1.filter("Add = 'USA' or Name = 'Jhon'").show()This will filter all the columns with having Name as Jhon and Add as the USA.
Screenshot:
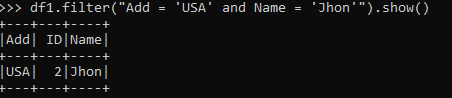
The same can be used with the AND operator also. This will filter data only when both the condition are True.
df1.filter("Add = 'USA' and Name = 'Jhon'").show()Screenshot:
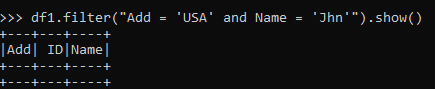
If any of the results are negative empty data Frame is Returned back.
df1.filter("Add = 'USA' and Name = 'Jhn'").show()Screenshot:
These are some of the Examples of Filter Function in PySpark.

