Introduction to PySpark Join
PySpark join operation is a way to combine Data Frame in a spark application.
A join operation basically comes up with the concept of joining and merging or extracting data from two different data frames or sources. It is used to combine rows in a Data Frame in Spark based on certain relational columns with it. The data satisfying the relation comes into the range while the other one gets eradicated.
PySpark join is very important to deal with bulk data or nested data coming up from two Data frames in Spark. A join operation has the capability of joining multiple data frames or working on multiple rows of a Data Frame in a PySpark application.
PySpark joins has various Types with which we can join a data frame and work over the data as per need. Some of the joins operations are:-
Inner Join, Outer Join, Right Join, Left Join, Right Semi Join, Left Semi Join, etc.
These operations are needed for Data operations over the Spark application. Let us check some examples of this operation over the PySpark application.
Examples of PySpark Joins
Let us see some Examples of how the PySpark Join operation works:
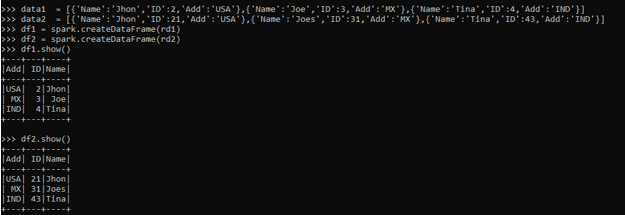
Before starting the operation let’s create two Data frames in PySpark from which the join operation example will start. Create a data Frame with the name Data1 and another with the name of Data2. createDataframe function is used in Pyspark to create a DataFrame.
Code:
data1 = [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'MX'},{'Name':'Tina','ID':4,'Add':'IND'}] data2 = [{'Name':'Jhon','ID':21,'Add':'USA'},{'Name':'Joes','ID':31,'Add':'MX'},{'Name':'Tina','ID':43,'Add':'IND'}]Create an RDD
rd1 = sc.parallelize(data1)
rd2 = sc.parallelize(data2)Create DataFrame from RDD
df1 = spark.createDataFrame(rd1)
df2 = spark.createDataFrame(rd2)
df1.show()
df2.show()Code SnapShot:
The Sample Data frame is created now let’s see the join operation and its usage.
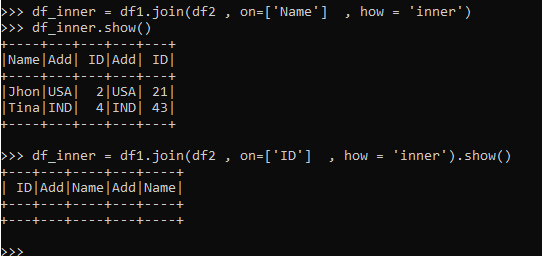
Inner Join
The Matching records from both the data frame is selected in Inner join.
The operation is performed on Columns and the column with the same value is joined with result being displayed as the output.
Code:
df_inner = df1.join(df2 , on=['Name'] , how = 'inner')
df_inner.show()
df_inner = df1.join(df2 , on=['ID'] , how = 'inner').show()The one matching the condition will come as a result and the one not will not.
Non-satisfying conditions are produced with no result.
Code Snapshot:
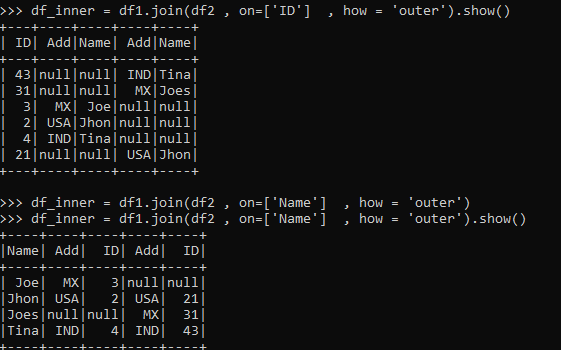
Outer Join
All the data from both the data frame is selected in Outer join.
The operation is performed on Columns and the matched columns are returned as result. Missing columns are filled with Null.
Code:
df_inner = df1.join(df2 , on=['ID'] , how = 'outer').show()
df_inner = df1.join(df2 , on=['Name'] , how = 'outer').show()The one matching the condition will come as a result and the one not will not.
Non-satisfying conditions are filled with null and the result is displayed.
Code Snapshot:
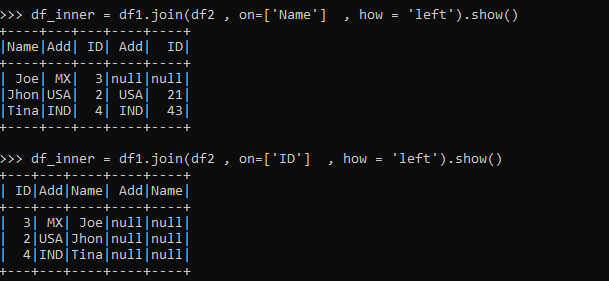
Left Join
All the data from Left data frame is selected and data that matches the condition and fills record in the matched case in Left Join.
The operation is performed on Columns and the matched columns are returned as result. Missing columns are filled with Null.
Code:
df_inner = df1.join(df2 , on=['Name'] , how = 'left').show()
df_inner = df1.join(df2 , on=['id'] , how = 'left').show()The one matching the condition will come as result and the one not will not.
Non-satisfying conditions are filled with null and the result is displayed. All the elements from the left data Frame will come in the result filling the values satisfied else null.
Code Snapshot:
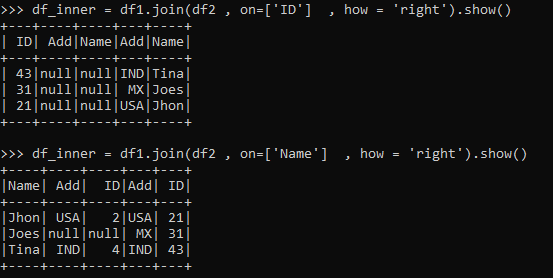
Right Join
All the data from Right data frame is selected and data that matches the condition and fills record in the matched case in Right Join.
The operation is performed on Columns and the matched columns are returned as result . Missing columns are filled with Null.
Code:
df_inner = df1.join(df2 , on=['Name'] , how = 'right').show()
df_inner = df1.join(df2 , on=['id'] , how = 'right').show()The one matching the condition will come as result and the one not will not.
Non-satisfying conditions are filled with null and the result is displayed. All the elements from the right data Frame will come in the result filling the values satisfied else null.
Code Snapshot:
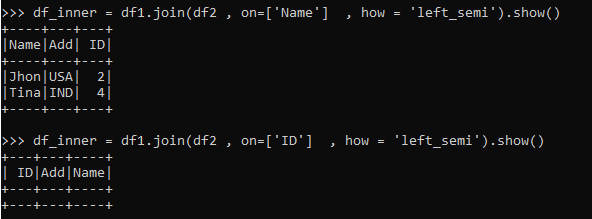
Left Semi Join
The Matching records from Left data frame is selected in Left Semi join.
The operation is just like the Inner Join just the selected data are from the left Data Frame.
Code:
df_inner = df1.join(df2 , on=['Name'] , how = ‘left_semi’).show()
df_inner = df1.join(df2 , on=['ID'] , how = 'left_semi').show()The one matching the condition will come as result (Only Left Data Frame Data) and the one not will not.
Non satisfying conditions are produced with no result.
Code Snapshot:
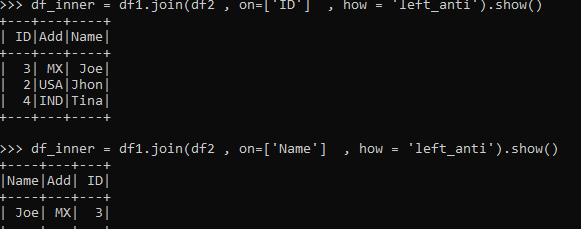
Left Anti Join
The difference of the record from both the data frame. It selects rows that are not in DataFrame2 from DataFrame1.
Code:
df_inner = df1.join(df2 , on=['Name'] , how = 'left_anti').show()
df_inner = df1.join(df2 , on=['ID'] , how = 'left_anti').show()Code Snapshot: