Introduction to PySpark mapPartitions
PySpark mapPartitions is a transformation operation that is applied to each and every partition in an RDD. It is a property of RDD that applies a function to the partition of an RDD. As we all know an RDD in PySpark stores data in partition and mapPartitions is used to apply a function over the RDD partition in PySpark architecture.
It can be applied only to an RDD in PySpark so we need to convert the data frame/dataset into an RDD to apply the MapPartitions to it. There is no data movement or shuffling while doing the MapPartitions. The same number of rows is returned as the output compared to the input row used.
In this article, we will try to analyze the various ways of using the mapPartitions operation PySpark.
Let us try to see about mapPartitions in some more detail.
Syntax of PySpark mapPartitions
The syntax for the mapPartitions function is:-
df2=b.rdd.mapPartitions(fun).toDF(["name","ID"])
b:- The Dataframe that is used post converted to RDD
mappartitions:- The MapPartitions to be used on the partition over the RDD partitions.
toDF:- The to Data frame conversion.
Df2:- The Final data frame formedScreenshot:-
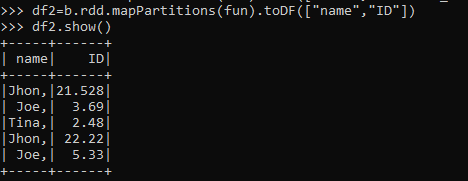
Working of PySpark mapPartitions
Let us see how mapPartitions works.
The mapPartitions is a transformation that is applied over particular partitions in an RDD of the PySpark model. This can be used as an alternative to map() and foreach().
The return type is the same as the number of rows in RDD. In MapPartitions the function is applied to a similar partition in an RDD, which improves the performance.
Heavy Initialization of data model that requires one-time calling over each partition is done by using the mapPartitions. RDD stores the data in the partition in which the operation is applied over each element but in MapPartitions the function is applied to every partition in an RDD data model.
A Connection to the database is an example that needs to be applied once over each partition that helps the data analysis further, the MapPartitions fits well with this model, and the connection is made based on the partition of data.
MapPartitions keeps the result in memory unless and until all the rows are processed in the Partition.
Let’s check the creation and working of MAPPARTITIONS with some coding examples.
Examples of PySpark mapPartitions
Let us see some examples of how mapPartitions operation works:-
Let’s start by creating simple data in PySpark.
>>> data1 = [{'Name':'Jhon','ID':21.528,'Add':'USA'},{'Name':'Joe','ID':3.69,'Add':'USA'},{'Name':'Tina','ID':2.48,'Add':'IND'},{'Name':'Jhon','ID':22.22, 'Add':'USA'},{'Name':'Joe','ID':5.33,'Add':'INA'}] A sample data is created with Name , ID and ADD as the field.
>>> a = sc.parallelize(data1)
RDD is created using sc.parallelize.
>>> b = spark.createDataFrame(a)
Created Data Frame using Spark.createDataFrame.Screenshot:-

Let’s create a simple function that takes name and ID and passes it over to the MapPartitions method.
This iterates over the rdd and yields the Name and ID from it.
def fun(p):
for row in p:
yield [row.Name+",",row.ID] We will convert this data frame into RDD and pass the mapPartitions function inside this. The post method toDF will create the RDD again with the name as the schema.
>>> df2=b.rdd.mapPartitions(fun).toDF(["name","Concated_Name"])Screenshot:-
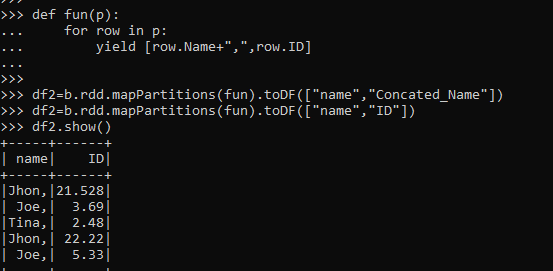
Let us try to see how the MapPartitions element can work over the partition data.
>>> rdd = sc.parallelize([1, 2, 3, 4,3,5,2,1,3], 3)
>>> def fun2(iterator): yield sum(iterator)
>>> rdd.mapPartitions(fun2).collect()The function returns the sum of elements listed in the partition of data.
Output:-
[6, 12, 6]Screenshot:-
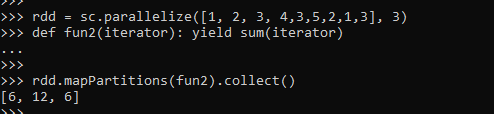
These are some of the Examples of mapPartitions.
This function can be used to create logics that can be applied once each partition like connection creation, termination of the connection.
Note
- mapPartitions is a transformation operation model of PySpark RDD.
- mapPartitions is applied over RDD in PySpark so that the Data frame needs to be converted to RDD.
- mapPartitions are applied over the logic or functions that are heavy transformations.
- mapPartitions is applied to a specific partition in the model rather than each and every row model in PySpark.
- mapPartitions keep the result in the partition memory.
- mapPartitions is a faster and cheap data processing model.

