Pandas is one of the most useful tools a data scientist can use. It provides several handy functionalities to extract information. Unfortunately, using Pandas requires data to be loaded into Data Frames, which aren’t great for handling massive quantities of data —quantities of data common at a company where you would need such data manipulation skills.
If you were to download a complete, massive dataset — perhaps store it as a .csv file — you would need to spend at least several minutes waiting for the file to complete download and be converted into a DataFrame by Pandas. On top of this, any operations you perform will be slow because Pandas has trouble dealing with these massive amounts of data and needs to run through every row.
A better solution? First query the database with SQL — the native, efficient processing language it likely runs on — then download a reduced dataset, if necessary, and use Pandas to operate on the smaller-scale tables it is designed to work on. While SQL is very efficient with large databases, it cannot replace the value of Panda’s plotting integration with other libraries and with the Python language in general.
In the case where we only need to find numerical answers, however, like the average cost of an item or how many employees receive commission but not an hourly wage above $40, there is (usually) no need to touch Pandas and a Python environment at all.
While most people’s knowledge of SQL stops at SELECT * FROM table WHERE id = ‘Bob’, one would be surprised by the functionalities that SQL offers.
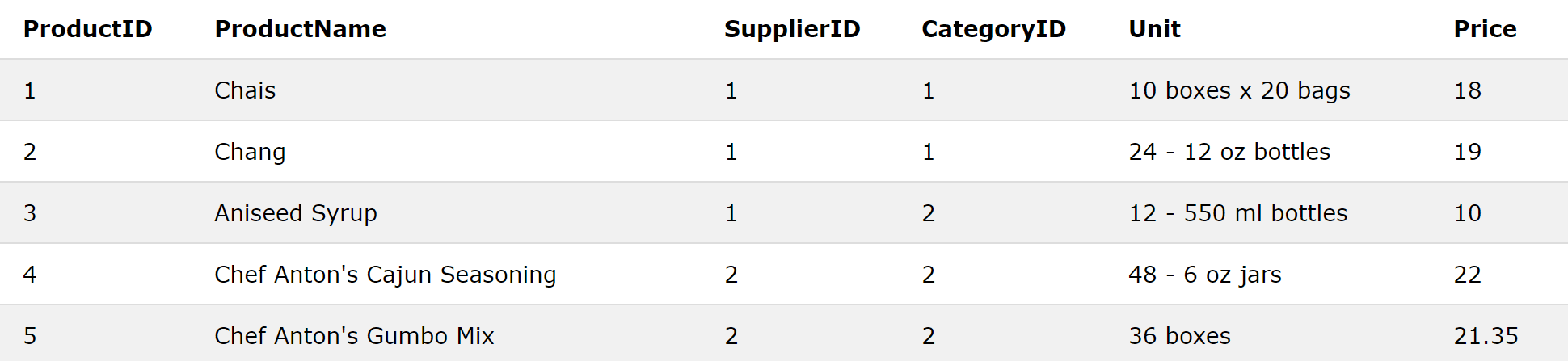
The table Customers has 7 columns with numerical and text data:

Say we want to send a prepared statement in the form of “Name LIVES IN Address, City”. This is simple: the double pipes operator || acts as a concatenation. Then, we can add column values and strings, and save the result under an alias,
or the column name of the result, using AS.
SELECT CustomerName || ‘ LIVES IN ‘ || Address || ‘, ‘ || City AS location FROM Customers WHERE Country=’Mexico’

Note that since we additionally specified Country=’Mexico’, our results are all of addresses and cities within Mexico. This type of operation would be more difficult and less easy to do in Python.
Note that not all databases support the same syntax. This article uses syntax for PostgreSQL, although every operation discussed has the operations in DB2, Oracle, MySQL, and SQL Server databases, sometimes with the same syntax, sometimes with different syntaxes. StackOverflow or Google can help you find these database-specific keywords.
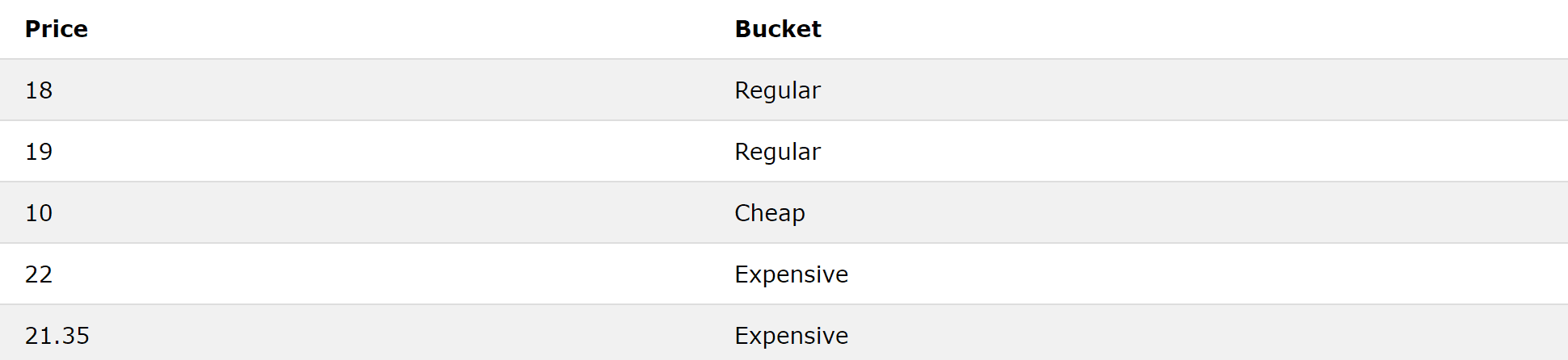
Say that, in the Products table, we want to group products into three price buckets: Cheap, Regular, and Expensive, for prices less than $12, between $12 and $21, and above $21, respectively.
No problem! The CASE keyword can help. This keyword acts like an if/else if/else statement in other languages like Python.
The CASE keyword uses the syntax WHEN condition THEN value. When multiple WHENs are stacked, they assume an ‘else-if’ relationship. Lastly, an ELSE value can be added if the condition is not met. Lastly, END is written to indicate the end of the CASE statement, and the results are saved (aliased) to a column named Bucket through AS Bucket.
SELECT Price, CASE WHEN Price < 12 THEN ‘Cheap’ WHEN Price < 21 THEN ‘Regular’ ELSE ‘Expensive’ END AS Bucket FROM Products
This could also be done in Pandas with .apply(), with much slower speed.
Say we want to randomly sample 5 rows from Products. Although there is no direct method to do this, we can get creative by using both the ORDER BY and LIMIT keywords. ORDER BY orders the data in a certain format; for instance, using ORDER BY Price ASC would order the data such that the price was in ascending format. Using DESC uses descending, and ORDER BY works with strings by sorting them alphabetically.
ORDER BY random() orders the data randomly, and LIMIT x returns the first x rows in the selected subset of data. This way, five random rows are selected from the data (* means all columns).
SELECT * FROM Products ORDER BY random() LIMIT 5
[highlight color=”yellow”]Note: Unfortunately, All Editor does not support random(), but real databases do (or use a variant, like rand()).[/highlight]
Like this task of randomly sampling, most of SQL is about chaining together several simpler commands like SELECT and integrating them with built-in functions to yield astonishingly complex results.
Moreover, SQL provides all the statistical functions you may need. With everything from MIN() to MAX() to COUNT() to SUM() to AVG() to ASIN() (arcsine), you’re set. You can either use package extensions for metrics like standard deviation or create them yourself using existing default functions, which is not difficult to do at all.
These are standard tasks — but what is more amazing is that SQL is a Turing-complete language. Put simply, you could represent a program in, say, Python or C++, in SQL, by building your own complex memory systems and using elements of SQL like functions, if/elses, recursion, etc. You can view some fascinating demonstrations of Turing-complete SQL here. The main point of this is not to encourage you to use SQL as an operational language, but to demonstrate that SQL can be used to do so much more than you thought.
There’s so much more that you can do in SQL that we haven’t discussed:
- Specify your own custom functions, like you would declare a function in Python or C++. These can be used to, for example, parse IP addresses.
- Use recursion to create complex looping and data generation with the
WITHkeyword. - Sort string columns by a substring.
- Perform complex joining between multiple tables.
- Use SQL to generate SQL (automating tasks).
- Generate forecasts using statistical models.
- Create histograms.
- Build tree structures (with leaf, branch, root nodes).
It’s true that you can do a lot more with SQL than you can with Pandas. That being said, usually that additional functionality is not necessary. The main reason why you should be using SQL is because it is built to handle large quantities of data in a custom environment that DataFrames are not.
Generally, SQL is a simple but sometimes very messy language, and it should usually be used just to reduce the size of the data until it becomes more manageable to handle in Pandas’ smaller environment.
Key Points
- Pandas isn’t good at handling big data, and its features can all be done with SQL. However, Pandas’ value comes from its integration with other plotting libraries, machine learning libraries, and the Python language.
- The goal should usually be to use SQL to narrow down a large dataset into one that is more relevant for the task, then to handle it in a Python environment, using Pandas’ data-frame as the basis for storage.
- Don’t be scared to touch SQL to handle big data problems. As demonstrated above, SQL’s syntax is simple and is almost all about chaining together simple commands to yield more complex results. If you have a clear vision of the result, you can make it happen with SQL.
- SQL can do a lot more than most people realize.