AWS Lambda
AWS Lambda is an event-driven, serverless compute service that lets you run code without provisioning or managing servers and can extend other AWS services with custom logic. Lambda can be automatically triggered in response to multiple events, such as HTTP requests through Amazon API Gateway, changes to data in Amazon S3 buckets or an Amazon DynamoDB table, or invoke your code using API calls made using AWS SDKs and state transitions in AWS Step Functions.
Lambda runs code on a highly available compute infrastructure, and performs all of the administration of the underlying platform, including server and operating system maintenance, capacity provisioning and automatic scaling, code monitoring and logging. With Lambda, you can just upload your code and configure when and how to invoke it. Lambda takes care of everything else required to run your code with high availability.
“Serverless” has been the buzz-word for several years now, with many applications choosing to implement the serverless approach. The term originated from the idea that the infrastructure used to run your backend code does not need to be provisioned and managed by you and your team. This significantly lessens the time it takes to get your application production-ready as well as the time and effort required to maintain your infrastructure. In 2014, Amazon Web Services released a product that would eventually become a gem in the wide pool of serverless solutions; that product is known as Lambda. In this article, we’ll take a look at why Lambda is worth your attention as well as the disadvantages you’ll want to consider, we’ll walk through the most prominent features of this service and explore its inner workings.
What is it?
As a brief overview, AWS Lambda is a function-based computing service that takes the efforts of provisioning and maintaining its infrastructure out of your hands. With Lambda, you don’t need to worry about scaling your infrastructure and removing unnecessary resources as this is all handled for you. We’ll take a deeper dive into how this service works, but first let’s take a look at why this tool is a worthy addition to your stack.
Advantages
Many of the advantages of using AWS Lambda relates to the advantages of adopting the serverless-approach in general. As mentioned in the intro, a major benefit of going serverless is the time and effort saved from creating and maintaining your infrastructure. AWS provisions and manages the infrastructure your Lambda functions run on, scales the instances to handle times of excessive load, and implements proper logging and error handling. Anyone that’s been involved in the creation or maintenance of infrastructure will understand the gravity of this advantage. Not only is there a large amount of time involved in building a system that suits the needs of your application, there is also a considerable amount of time required to maintain that system as your application evolves. Time saved means quicker time to market for your application, greater agility as your team is able to most faster, and more time spent on more important tasks such as bug fixes or new features.
As for why AWS Lambda is one of the most popular serverless solutions, AWS has done a very good job of ensuring Lambda accommodates applications at scale as well as applications in early stages. For applications with large amounts of load, AWS allows you to run your Lambda function simultaneously with other Lambda functions; meaning, you won’t need to worry about clogged-up queues. Not only that, multiple instances of the same Lambda function can be provisioned and run at the same time. Both advantages ensure that no matter how much load your application is under, Lambda will be able to handle it. Another advantage of using AWS Lambda is that you only pay for what you need, accomodating for applications that are not yet at scale or have widely differing loads. AWS charges you for the number of requests your Lambda functions receive and the time it takes to execute those requests per 100ms. Despite its wide array of advantages, there isn’t a single solution that exists without its share of disadvantages and AWS Lambda is no exception.
Disadvantages
Moving the task of maintaining your infrastructure away from your team and in the hands of a provider results in less control and flexibility, which is the biggest disadvantage of the serverless approach. On top of that, services that help implement the serverless approach come with their own set of infrastructure-related limitations; in Lambda’s case, these limitations are the following:
- Functions will timeout after 15 minutes.
- The amount of RAM available ranges from 128MB to 3008MB with a 64MB increment between each option.
- The Lambda code should not exceed 250mb in size, and the zipped version should be no larger than 50mb
- There is a limit of 1,000 requests that can run concurrently, any request above this limit will be throttled and will need to wait for other functions to finish running.
Whether or not these limitations will impact your application is dependent on the nature of your Lambda functions; usually, the solution is to refactor your Lambda functions to improve their efficiency. If any of these limitations begin to impact your Lambda functions, the first thing to do is to investigate why and whether your functions could be improved. For example, is the reason your function is timing out is that there’s inefficient algorithms involved? Are there any unnecessary dependencies in your Lambda code, causing its size to exceed the limit?
Cost was mentioned in our list of advantages, but although you only pay for what your application requires this does not necessarily result in a cost effective solution; during times of high load, the cost of the same infrastructure on AWS EC2 or other services may be cheaper. The price of other services based on your application’s needs should be considered especially if your application experiences a consistently high load. The final disadvantage worth mentioning is the small latency time between when an event occurs and when the function runs. This small latency times only occurs in some cases — during a cold start. In most cases, these latency times are so minuscule that it’s hardly an issue but it’s still worth considering if your application is already bordering on potential load problems; I’ll talk about cold starts in more detail in a later section.

When to use Lambda?
AWS Lambda is a suitable computing platform for many application scenarios provided that you can write your application code in languages and runtime environments supported by the service. When you want to focus only on your application code, on your business logic, and leave the server maintenance, provisioning and scalability to others for a good price, then you definitely need to migrate to AWS Lambda.
Lambda is perfect for building APIs, together with API Gateway you can efficiently achieve fast time to market and optimize costs. There are different ways for using Lambda functions, different serverless design patterns which everyone could follow depending on their needs.
A variety of tasks could be implemented with Lambda functions. You can create cron job with the help of CloudWatch and automate some processes. There are no restrictions for usage flows (you have for memory and time) and going to full-fledged microservices applications using Lambda is nice and smooth.
The typical example with image resizing and Lambda shows we can create service-oriented actions which don’t have to be running all the time. Even for distributed systems Lambda functions are good choice.
So, you have no need for provisioning and managing of computing resources — try AWS Lambda; you don’t execute heavy processing consuming resources — try AWS Lambda; your code doesn’t execute every second — try AWS Lambda.
How does it work?
If you’ve decided that Lambda may be a worthy addition to your stack, the next step is to understand the inner workings of a Lambda function. On a very basic level, serverless applications are made up of 2 or 3 components; these are event sources, functions and (in some cases) services. An event source encapsulates anything that can invoke a function, such as uploads to an S3 bucket, changes to data state, or requests to an endpoint. When any one of the designated events occurs, your Lambda function will run in its own container. The resources allocated to that container and the number of containers used is determined by the size of the data and the computational requirements of the function, this is all handled by AWS. Once the request is completed, your Lambda function will either return a result back to the invocation source or a connected service, or it could make changes to a connected service (such as a database).

Before you can run a Lambda function, you’ll need to create one and to successfully do so, you’ll need a basic understanding of what’s involved. A Lambda function consists of 3 or 4 parts; the handler function, the event object, the context object and in some cases a callback function. The handler function is the function that will be executed upon invocation, this can either be async or non-async. Asynchronous functions take an event object and a context object whereas non-asynchronous functions take both these objects and a callback function. The event object contains data that was sent when the function’s event was triggered, this includes information such as the request body and the uri, the data that is passed through depends on the invocation service. The context object contains runtime information such as the function name, function version and log group. The callback function is only passed through to synchronous handlers and it takes two arguments: an error and a response. Once the Lambda function is created and pushed up to AWS, it is compressed along with its dependencies and stored in an S3 bucket.
async-handler .js
const fetchData = require('./fetch.js')
exports.handler = async (event, context) => {
return await fetchData(event, context)
}
non-async-handler.js
exports.handler = function(event, context, callback) {
try {
// your code would go here
callback(null, res)
} catch(err) {
callback(err)
}
}
Note: For non-async handlers, function execution continues until the event loop is empty or the function times out.
Lambda Runtime Environment
The biggest benefit is when Lambda executes the function on your behalf, it manages the provisioning of the resources necessary to run your code. This focuses the developers on business logic and writing code, not administering systems.
The Lambda service is divided into two control planes. The control plane is the part of a network that carries signaling traffic and is responsible for routing. That’s by wiki description. More specific a control plane is the master component responsible for making global decisions about provisioning, maintaining and distributing a workload. It is also a network topology for a solution provider design responsible for routing and traffic management.
And Lambda service is split into the control plane and the data plane. As each plane serves a distinct purpose in the service. The control plane provides the function management APIs (CreateFunction, UpdateFunctionCode ), and manages integrations with all AWS services. The data plane controls the Invoke API that runs Lambda functions. When a Lambda function is invoked, the data plane allocates an execution environment to that function, or chooses an existing execution environment that has already been set up for that function, then runs the function code in that environment.
AWS Lambda provides support for multiple programming languages through the use of runtimes, including Java 8, Python 3.7, Go, NodeJS 8, .NET core 2, and others. Lambda provides support for these runtimes, including updates, security patches, and other maintenance. You can use other languages in Lambda by implementing a custom runtime. For custom runtimes, maintenance becomes your responsibility, including making sure that the runtime you provide includes the latest security patches.
But how things work, how our functions are executed under the hood?
Each function runs in one or more dedicated execution environments that are used for the lifetime of the function and then destroyed. Each execution environment hosts one concurrent invocation but is reused in place across multiple serial invocations of the same function. Execution environments run on hardware virtualized virtual machines (microVMs). A micro VM is dedicated to an AWS account but can be reused by execution environments across functions within an account. MicroVMs are packed onto an AWS-owned and managed hardware platform (Lambda Workers). Execution environments are never shared across functions and microVMs are never shared across AWS accounts.
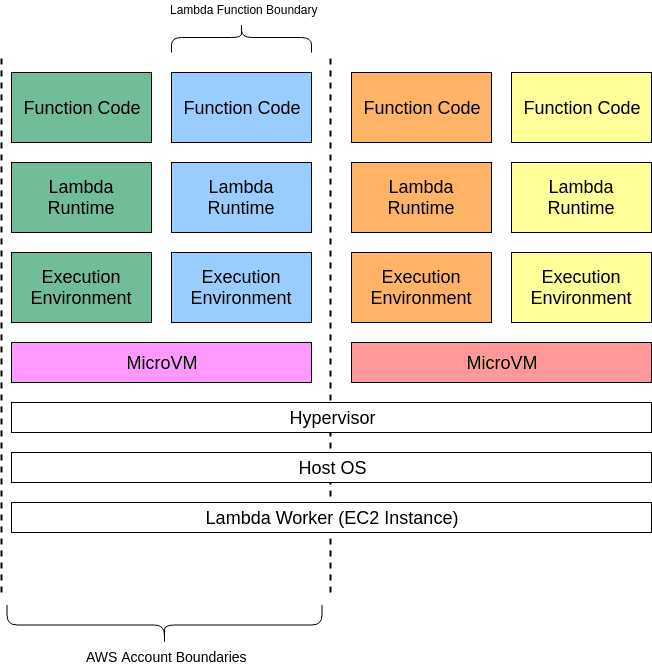
The isolation is made using several techniques. At high level each execution environment contains a dedicated copy of the following items:
- The function code
- Any Lambda layers selected for your function
- The function runtime
- A minimal Linux userland based on Amazon Linux
Execution environments are isolated from one another using:
- cgroups — Constrain resource access to limiting CPU, memory, disk throughput, and network throughput, per execution environment
- namespaces — Group process IDs, user IDs, network interfaces, and other resources managed by the Linux kernel. Each execution environment runs in a dedicated namespace
- seccomp-bpf — Limit the syscalls that can be used from within the execution environment
- iptables and routing tables — Isolate execution environments from each other
- chroot — Provide scoped access to the underlying filesystem
Along with AWS proprietary isolation technologies, these mechanisms provide strong isolation between execution environments. This isolation ensures that environments are not able to access or modify data that belongs to other environments.
Although multiple execution environments from a single AWS account can run on a single microVM, microVMs are never shared or reused between AWS accounts. At this time, AWS Lambda uses two different mechanisms for isolating microVMs: EC2 instances and Firecracker. EC2 instances have been used for Lambda guest isolation since 2015. Firecracker is a new open source hypervisor developed by AWS especially for serverless workloads, and was introduced in 2018. The underlying physical hardware running microVMs will be shared by workloads from multiple accounts.
Storage and State
Even though Lambda execution environments are never reused across functions, a single execution environment can be reused for invoking the same function, potentially existing for hours before it is destroyed.
Each Lambda execution environment also includes a writeable file system, available at /tmp. This storage is not accessible to other execution environments. As with the process state, files written to /tmp remain for the lifetime of the execution environment. This allows expensive transfer operations — such as downloading machine learning (ML) models — to be amortized across multiple invocations.
Invoke Data Path
The Invoke API can be called in two modes: event mode and request-response mode. Event mode queues the invocation for later execution. Request-response mode immediately invokes the function with the provided payload, and returns the response. In both cases, the actual function execution is done in a Lambda execution environment, but the payload takes different paths.
For request-response invocations, the payload passes from the API caller — such as AWS API Gateway or the AWS SDK — to a load balancer, and then to the Lambda invoke service. This service identifies an execution environment for the function, and passes the payload to that execution environment to complete the invocation. Traffic to the load balancer passes over the internet, and is secured with TLS. Traffic within the Lambda service (from the load balancer down) passes through a Lambda internal VPC within a single AWS region.
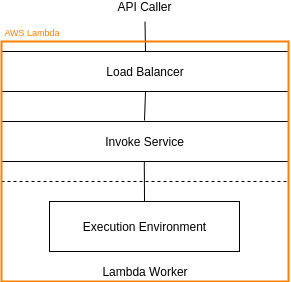
Event invocations can be executed immediately or queued for processing. In some cases, the queue is implemented with Amazon Simple Queue Service (Amazon SQS), and passed back to the Lambda invoke service by an internal poller process. Traffic on this path is secured with TLS, but no additional encryption is provided for data stored in Amazon SQS. For event invokes, no response is returned, and any response data is discarded by the worker. Invocations from Amazon S3, Amazon SNS, CloudWatch events, and other event sources follow the event invoke path in the Lambda service. Invocations from Amazon Kinesis and DynamoDB streams, SQS queues, Application Load Balancer, and API Gateway follow the request-response path.
Layers
Once you start to build your Lambda functions you’ll notice that there are pieces of logic that could be shared between multiple functions, this is when layers can come in handy. Layers allow you to reuse code across several functions without needing an additional invocation. Once you’ve identified a piece of code that could be reused, implement it as a layer and attach it to the functions that need it. A layer is created in the same fashion as a Lambda function, with slight configuration changes which depend on the method you’ve chosen to deploy your functions (via AWS’s GUI, using the serverless framework, or AWS’s CLI tool). This is also true for adding a layer to a function; it can easily be done via AWS’s GUI, by adding a few extra lines to the serverless.yml file if you’re using the serverless framework, or with a single command using their CLI tool. The use of layers can help improve the maintainability and cleanliness of your Lambda functions as you’ll be able to significantly lessen the amount of code necessary for each function as well as the amount of duplicate code across your application.
Versioning and Aliases
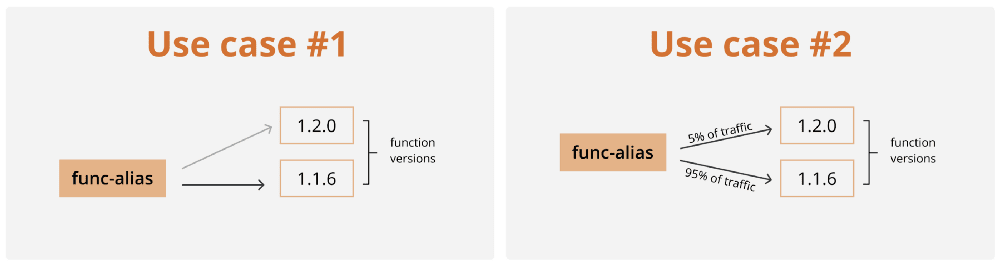
AWS not only allows you to save different versions of your Lambda functions but also allows these versions to coexist and run at the same time, this gives consumers of your functions the flexibility to upgrade to newer versions as they please. Aliases are used as a pointer to a particular version of a Lambda function, there is a long list of use cases in which they can be utilized in; two of which is worth mentioning. Firstly, instead of updating the version of a function everywhere, it’s called you could use an alias in these areas and update the version that the alias points to. Secondly, aliases have the ability to point to two versions and give you the flexibility to determine the percentage of traffic to be sent to each version. This can be very useful if you and your team wanted to test a new version of a function with a small percentage of your traffic before releasing the new version universally.
Permissions
Relatively speaking, your Lambda functions are considerably secure by default; your function can’t talk to other services nor can it be invoked by any client, you’ll have to enable it to do so. Permissions surrounding your Lambda functions fall into two buckets: execution policies and resource-based policies. Execution policies determine which services and resources a Lambda function has access to, as well as which event sources can trigger a Lambda function to run. Resource-based policies grant other accounts and AWS services access to your Lambda resources, these include functions, versions, aliases and layer versions.
Resilience
AWS helps to ensure that your Lambda function is able to handle faults without impacting your entire application using a set of features they’ve included into Lambda. The most notable features have already been mentioned in this article and those are Lambda’s scalability, versioning and ability to run concurrently. A couple of other features that contribute to the service’s resilience is their use of multiple availability zones and the ability to reserve concurrency. By default, AWS runs your Lambda functions in multiple availability zones, this ensures that your functions are not impacted if a single zone is down; the same cannot be said for services such as EC2 where this behavior must be set by the developer. With Lambda, developers have the ability to set reserved concurrency for a particular function which ensures that it can always scale to (but not exceed past) a set number of concurrent invocations despite the number of requests other functions are consuming — note that AWS will still adhere to the upper limit of 1,000 requests, which means requests for other functions will be throttled.
Cold Starts
Cold starts occur when a function has been idle for a long enough period of time that its container has been completely terminated. A new container is provisioned when the function is invoked resulting in a small amount of latency. At times, an idle Lambda container is available to pick up new requests; if this is the case, provisioning a new container isn’t necessary — this is called a warm start. The period of time a Lambda function can be idle for before it gets terminated isn’t well-documented but an experiment in 2017 found that most functions were terminated after 45–60 minutes of inactivity; potentially earlier if resources are needed by other customers. The amount of time it takes for a function to start up is influenced by its scripting language, whether the function is outside of a VPC (if it is, start-up time will be faster), how big the package size is and how much memory is allocated to the function. Whether or not your application will likely experience cold starts depends on the amount of variation between your load levels. A fairly constant amount of load will mean that your application will require the same number of containers most of the time, which results in more warm starts as a container will likely be available for most requests.
Security
So far so good. But the managed runtime environment model of AWS Lambda doesn’t show what’s under the hood and intentionally hides many implementation details from the user, making some of the existing best practices for cloud security irrelevant.
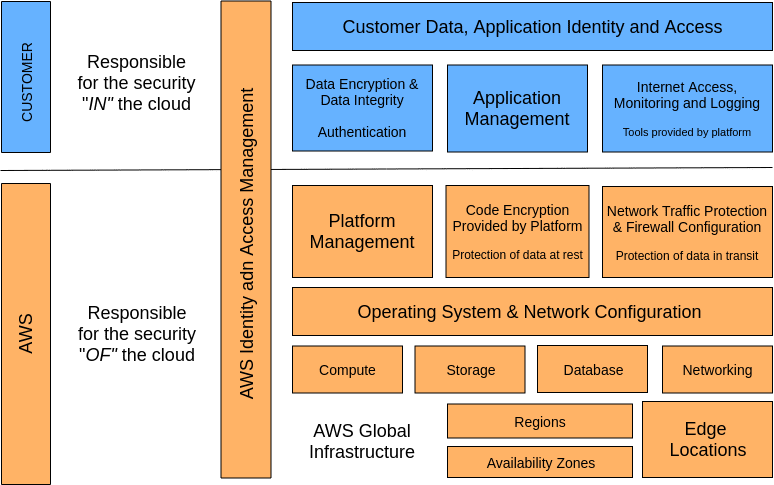
As in almost every AWS service Lambda follows the shared responsibility Security and Compliance between AWS and the customer. This shared responsibility model can help relieve your operational burden as AWS operates, manages, and controls the components from the host operating system and virtualization layer, down to the physical security of the facilities in which the service operates. For AWS Lambda, AWS manages the underlying infrastructure and foundation services, the operating system and the application platform. You are responsible for the security of your code, the storage and accessibility of sensitive data and identity and access management (IAM) to the Lambda service and within your function.
The figure below shows the shared responsibility model for AWS Lambda. AWS responsibilities appear in orange and customer responsibilities appear in blue. AWS assumes more responsibility for applications deployed to Lambda.
Monitoring
You can monitor and audit Lambda functions with many AWS methods and services, including the following services:
- Amazon CloudWatch
It reports metrics such as the number of requests, the execution duration per request, and the number of requests resulting in an error. - Amazon CloudTrail
CloudTrail enables you to log, continuously monitor, and retain account activity related to actions across your AWS infrastructure, providing a complete event history of actions taken through the AWS Management Console, AWS SDKs, command-line tools, and other AWS services. - AWS X-Ray
X-Ray’s end-to-end view of requests as they travel through your application shows a map of the application’s underlying components, so you can analyze applications during development and in production. - AWS Config
With AWS Config, you can track configuration changes to the Lambda functions (including deleted functions), runtime environments, tags, handler name, code size, memory allocation, timeout settings, and concurrency settings, along with Lambda IAM execution role, subnet, and security group associations.
Conclusion
AWS Lambda offers a powerful toolkit for building secure and scalable applications. Many of the best practices for security and compliance in AWS Lambda are the same as in all AWS services, but some are particular to Lambda. As of March 2019, Lambda is compliant with SOC 1, SOC 2, SOC 3, PCI DSS, U.S. Health Insurance Portability and Accountability Act (HIPAA), etc. As you think about your next implementation, consider what you have learned about AWS Lambda and how it might improve your next workload solution.




Nice article .. thanks for sharing such detailed explanation of aws lambda.