AWS Certified Developer Associate Exam Question and Answers with Explanation

Question
A developer is planning to use a Lambda function to process incoming requests from an Application Load Balancer (ALB). How can this be achieved?
1: Create a target group and register the Lambda function using the AWS CLI 2: Create an Auto Scaling Group (ASG) and register the Lambda function in the launch configuration
3: Setup an API in front of the ALB using API Gateway and use an integration request to map the request to the Lambda function
4: Configure an event-source mapping between the ALB and the Lambda function
Answer: 1
Explanation:
You can register your Lambda functions as targets and configure a listener rule to forward requests to the target group for your Lambda function. When the load balancer forwards the request to a target group with a Lambda function as a target, it invokes your Lambda function and passes the content of the request to the Lambda function, in JSON format.
You need to create a target group, which is used in request routing, and register a Lambda function to the target group. If the request content matches a listener rule with an action to forward it to this target group, the load balancer invokes the registered Lambda function.
CORRECT: “Create a target group and register the Lambda function using the AWS CLI” is the correct answer.
INCORRECT: “Create an Auto Scaling Group (ASG) and register the Lambda function in the launch configuration” is incorrect as launch configurations and ASGs are used for launching Amazon EC2 instances, you cannot use an ASG with a Lambda function.
INCORRECT: “Setup an API in front of the ALB using API Gateway and use an integration request to map the request to the Lambda function” is incorrect as it is not a common design pattern to map an API Gateway API to a Lambda function when using an ALB. Though technically possible, typically you would choose to put API Gateway or an ALB in front of your application, not both.
INCORRECT: “Configure an event-source mapping between the ALB and the Lambda function” is incorrect as you cannot configure an event-source mapping between and ALB and a Lambda function.
Question
A developer is troubleshooting problems with a Lambda function that is invoked by Amazon SNS and repeatedly fails. How can the developer save discarded events for further processing?
1: Enable CloudWatch Logs for the Lambda function 2: Configure a Dead Letter Queue (DLQ)
3: Enable Lambda streams
4: Enable SNS notifications for failed events
Answer: 2
Explanation:
You can configure a dead letter queue (DLQ) on AWS Lambda to give you
more control over message handling for all asynchronous invocations, including those delivered via AWS events (S3, SNS, IoT, etc.).
A dead-letter queue saves discarded events for further processing. A dead- letter queue acts the same as an on-failure destination in that it is used when an event fails all processing attempts or expires without being processed.
However, a dead-letter queue is part of a function’s version-specific configuration, so it is locked in when you publish a version. On-failure destinations also support additional targets and include details about the function’s response in the invocation record.
You can setup a DLQ by configuring the ‘DeadLetterConfig’ property when creating or updating your Lambda function. You can provide an SQS queue or an SNS topic as the ‘TargetArn’ for your DLQ, and AWS Lambda will write the event object invoking the Lambda function to this endpoint after the standard retry policy (2 additional retries on failure) is exhausted.
CORRECT: “Configure a Dead Letter Queue (DLQ)” is the correct answer.
INCORRECT: “Enable CloudWatch Logs for the Lambda function” is incorrect as CloudWatch logs will record metrics about the function but will not record records of the discarded events.
INCORRECT: “Enable Lambda streams” is incorrect as this is not something that exists (DynamoDB streams does exist).
INCORRECT: “Enable SNS notifications for failed events” is incorrect. Sending notifications from SNS will not include the data required for troubleshooting. A DLQ is the correct solution.
Question
A company will be uploading several terabytes of data to Amazon S3. What is the SIMPLEST solution to ensure that the data is encrypted before it is sent to S3 and whilst in transit?
1: Use client-side encryption with a KMS managed CMK and SSL 2: Use server-side encryption with client provided keys
3: Use client-side encryption and a hardware VPN to a VPC and an S3 endpoint
4: Use server-side encryption with S3 managed keys and SSL
Answer: 1
Explanation:
Client-side encryption is the act of encrypting data before sending it to Amazon S3. You have the following options:
Use a customer master key (CMK) stored in AWS Key Management Service (AWS KMS).
Use a master key you store within your application.
Additionally, using HTTPS/SSL to encrypt the data as it is transmitted over the Internet adds an additional layer of protection.
CORRECT: “Use client-side encryption with a KMS managed CMK and SSL” is the correct answer.
INCORRECT: “Use server-side encryption with client provided keys” is incorrect as this will encrypt the data as it is written to the S3 bucket. The questions states that you need to encrypt date before it is sent to S3.
INCORRECT: “Use client-side encryption and a hardware VPN to a VPC and an S3 endpoint” is incorrect. You can configure a hardware VPN to a VPC and configure an S3 endpoint to access S3 privately (rather than across the Internet). However, this is certainly not the simplest solution. Encrypting the data using client-side encryption and then using HTTPS/SSL to transmit the data is operationally easier to configure and manage and provides ample security.
INCORRECT: “Use server-side encryption with S3 managed keys and SSL” is incorrect as this does not encrypt the data before it is sent to S3 which is a requirement.
Question
An EC2 instance is allowed to access several buckets in an AWS account. The IAM policy attached to the EC2 instance profile’s IAM role was replaced a few hours ago and restricts access to a single S3 bucket.
However, the instance is still able to access all buckets. What is the MOST likely explanation for this? (Select TWO)
1: There is another policy attached to the IAM role that allows access 2: The evaluation logic checked the IAM user identity-based policy and found an allow
3: A resource-based policy attached to the S3 bucket is allowing access
4: IAM is eventually consistent, the changes may not have synchronized yet 5: It is not possible to restrict access to multiple buckets from a single policy
Answer: 1,3
Explanation:
Assume that a principal sends a request to AWS to access a resource in the same account as the principal’s entity. The AWS enforcement code decides whether the request should be allowed or denied. AWS gathers all of the policies that apply to the request context. The following is a high-level summary of the AWS evaluation logic on those policies within a single account.
By default, all requests are implicitly denied.
An explicit allow in an identity-based or resource-based policy overrides this default.
If a permissions boundary, Organizations SCP, or session policy is present, it might override the allow with an implicit deny.
An explicit deny in any policy overrides any allows.
In this case the most likely explanation is that either another policy attached to the role has an allow rule allowing access to the buckets, or the bucket has a resource-based policy attached to it that is allowing access to the buckets.
CORRECT: “There is another policy attached to the IAM role that allows access” is a correct answer.
CORRECT: “A resource-based policy attached to the S3 bucket is allowing access” is also a correct answer.
INCORRECT: “The evaluation logic checked the IAM user identity-based policy and found an allow” is incorrect as the EC2 instance is using a role, not a user account.
INCORRECT: “IAM is eventually consistent, the changes may not have synchronized yet” is incorrect. Yes, IAM is eventually consistent however the question states that the changes were made a few hours ago which is ample time for IAM to synchronize.
INCORRECT: “It is not possible to restrict access to multiple buckets from a single policy” is incorrect. This is not true; you can certainly do this using multiple resources in the policy.
Question
A company is setting up a Lambda function that will process events from a DynamoDB stream. The Lambda function has been created and a stream has been enabled. What else needs to be done for this solution to work?
1: An alarm should be created in CloudWatch that sends a notification to Lambda when a new entry is added to the DynamoDB stream
2: An event-source mapping must be created on the DynamoDB side to associate the DynamoDB stream with the Lambda function
3: An event-source mapping must be created on the Lambda side to associate the DynamoDB stream with the Lambda function
4: Update the CloudFormation template to map the DynamoDB stream to the
Lambda function
Answer: 3
Explanation:
An event source mapping is an AWS Lambda resource that reads from an
event source and invokes a Lambda function. You can use event source mappings to process items from a stream or queue in services that don’t invoke Lambda functions directly. Lambda provides event source mappings for the following services. Services That Lambda Reads Events From Amazon Kinesis Amazon DynamoDB Amazon Simple Queue Service. An event source mapping uses permissions in the function’s execution role to read and manage items in the event source. Permissions, event structure, settings, and polling behavior vary by the event source.
The configuration of the event source mapping for stream-based services (DynamoDB, Kinesis), and Amazon SQS, is made on the Lambda side.
Note: for other services, such as Amazon S3 and SNS, the function is invoked asynchronously and the configuration is made on the source (S3/SNS) rather than Lambda.
CORRECT: “An event-source mapping must be created on the Lambda side to associate the DynamoDB stream with the Lambda function” is the correct answer.
INCORRECT: “An alarm should be created in CloudWatch that sends a notification to Lambda when a new entry is added to the DynamoDB stream” is incorrect as you should use an event-source mapping between Lambda and DynamoDB instead.
INCORRECT: “An event-source mapping must be created on the DynamoDB side to associate the DynamoDB stream with the Lambda function” is incorrect because for stream-based services that don’t invoke Lambda functions directly, the configuration should be made on the Lambda side.
INCORRECT: “Update the CloudFormation template to map the DynamoDB stream to the Lambda function” is incorrect as CloudFormation may not even be used in this scenario (it wasn’t mentioned) and wouldn’t continuously send events from DynamoDB streams to Lambda either.
Question
A developer is preparing to deploy a Docker container to Amazon ECS using CodeDeploy. The developer has defined the deployment actions in a JSON file. What should the developer name the file?
1: buildspec.yml
3: appspec.yaml
3: cron.yml
4: appspec.yml
Answer: 2
Explanation:
The application specification file (AppSpec file) is a YAML-formatted or JSON-formatted file used by CodeDeploy to manage a deployment. The AppSpec file defines the deployment actions you want AWS CodeDeploy to execute.
The name of the AppSpec file for an EC2/On-Premises deployment must be appspec.yml. The name of the AppSpec file for an Amazon ECS or AWS Lambda deployment must be appspec.yaml.
Therefore, as this is an ECS deployment the file name must be appspec.yaml.
CORRECT: “appspec.yaml” is the correct answer.
INCORRECT: “buildspec.yml” is incorrect as this is the file name you should use for the file that defines the build instructions for AWS CodeBuild.
INCORRECT: “cron.yml” is incorrect. This is a file you can use with Elastic Beanstalk if you want to deploy a worker application that processes periodic background tasks.
INCORRECT: “appspec.yml” is incorrect as the file extension for ECS or Lambda deployments should be “.yaml”, not “.yml”.
Question
A decoupled application is using an Amazon SQS queue. The processing layer that is retrieving messages from the queue is not able to keep up with the number of messages being placed in the queue. What is the FIRST step the developer should take to increase the number of messages the application receives?
1: Use the API to update the WaitTimeSeconds parameter to a value other than 0
2: Add additional Amazon SQS queues and have the application poll those queues
3: Use the ReceiveMessage API to retrieve up to 10 messages at a time 4: Configure the queue to use short polling
Answer: 3
Explanation:
The ReceiveMessage API call retrieves one or more messages (up to 10), from the specified queue. This should be the first step to resolve the issue. With more messages received with each call the application should be able to process messages faster.
If the application still fails to keep up with the messages, and speed is important (remember this is one of the reasons for using an SQS queue, to shield your processing layer for the front-end), then additional queues can be added to scale horizontally.
CORRECT: “Use the ReceiveMessage API to retrieve up to 10 messages at a time” is the correct answer.
INCORRECT: “Use the API to update the WaitTimeSeconds parameter to a value other than 0” is incorrect as this is used to configure long polling.
INCORRECT: “Add additional Amazon SQS queues and have the application poll those queues” is incorrect as this may not be the first step. It would be simpler to update the application code to pull more messages at a time before adding queues.
INCORRECT: “Configure the queue to use short polling” is incorrect as this will not help the application to receive more messages.
Question
An application uses AWS Lambda which makes remote to several downstream services. A developer wishes to add data to custom subsegments in AWS X-Ray that can be used with filter expressions. Which type of data should be used?
1: Metadata
2: Annotations
3: Trace ID
4: Daemon
Answer: 2
Explanation:
AWS X-Ray helps developers analyze and debug production, distributed applications, such as those built using a microservices architecture. With X- Ray, you can understand how your application and its underlying services are performing to identify and troubleshoot the root cause of performance issues and errors. X-Ray provides an end-to-end view of requests as they travel through your application and shows a map of your application’s underlying components.
You can record additional information about requests, the environment, or your application with annotations and metadata. You can add annotations and metadata to the segments that the X-Ray SDK creates, or to custom subsegments that you create.
Annotations are key-value pairs with string, number, or Boolean values. Annotations are indexed for use with filter expressions. Use annotations to record data that you want to use to group traces in the console, or when calling the GetTraceSummaries API.
CORRECT: “Annotations” is the correct answer.
INCORRECT: “Metadata” is incorrect. Metadata are key-value pairs that can have values of any type, including objects and lists, but are not indexed for use with filter expressions. Use metadata to record additional data that you want stored in the trace but don’t need to use with search.
INCORRECT: “Trace ID” is incorrect. An X-Ray trace ID is used to group a set of data points in AWS X-Ray.
INCORRECT: “Daemon” is incorrect as this is a software application that listens for traffic on UDP port 2000, gathers raw segment data, and relays it to the AWS X-Ray API.
Question
An application component writes thousands of item-level changes to a DynamoDB table per day. The developer requires that a record is maintained of the items before they were modified. What MUST the developer do to retain this information? (Select TWO)
1: Create a CloudWatch alarm that sends a notification when an item is modified
2: Enable DynamoDB Streams for the table
3: Set the StreamViewType to OLD_IMAGE
4: Set the StreamViewType to NEW_AND_OLD_IMAGES
5: Use an AWS Lambda function to extract the item records from the notification and write to an S3 bucket
Answer: 2,3
Explanation:
DynamoDB Streams captures a time-ordered sequence of item-level modifications in any DynamoDB table and stores this information in a log for up to 24 hours. Applications can access this log and view the data items as they appeared before and after they were modified, in near-real-time.
You can also use the CreateTable or UpdateTable API operations to enable or modify a stream. The StreamSpecification parameter determines how the stream is configured:
StreamEnabled — Specifies whether a stream is enabled (true) or disabled (false) for the table.
StreamViewType — Specifies the information that will be written to the stream whenever data in the table is modified:
KEYS_ONLY — Only the key attributes of the modified item. NEW_IMAGE — The entire item, as it appears after it was modified.
OLD_IMAGE — The entire item, as it appeared before it was modified.
NEW_AND_OLD_IMAGES — Both the new and the old images of the item.
In this scenario, we only need to keep a copy of the items before they were modified. Therefore, the solution is to enable DynamoDB streams and set the StreamViewType to OLD_IMAGES.
CORRECT: “Enable DynamoDB Streams for the table” is the correct answer.
CORRECT: “Set the StreamViewType to OLD_IMAGE” is the correct answer.
INCORRECT: “Create a CloudWatch alarm that sends a notification when an item is modified” is incorrect as DynamoDB streams is the best way to capture a time-ordered sequence of item-level modifications in a DynamoDB table.
INCORRECT: “Set the StreamViewType to NEW_AND_OLD_IMAGES” is incorrect as we only need to keep a record of the items before they were modified. This setting would place a record in the stream that includes the item before and after modification.
INCORRECT: “Use an AWS Lambda function to extract the item records from the notification and write to an S3 bucket” is incorrect. There is no requirement to write the updates to S3 and if you did want to do this with Lambda you would need to extract the information from the stream, not a notification.
Question
An X-Ray daemon is being used on an Amazon ECS cluster to assist with debugging stability issues. A developer requires more detailed timing information and data related to downstream calls to AWS services. What should the developer use to obtain this extra detail?
1: Subsegments
2: Annotations
3: Metadata
4: Filter expressions
Answer: 1
Explanation:
A segment can break down the data about the work done into subsegments. Subsegments provide more granular timing information and details about downstream calls that your application made to fulfill the original request. A subsegment can contain additional details about a call to an AWS service, an external HTTP API, or an SQL database. You can even define arbitrary subsegments to instrument specific functions or lines of code in your application.
CORRECT: “Subsegments” is the correct answer.
INCORRECT: “Annotations” is incorrect. Annotations are simple key-value pairs that are indexed for use with filter expressions. Use annotations to record data that you want to use to group traces in the console, or when calling the the GetTraceSummaries API.
INCORRECT: “Metadata” is incorrect. Metadata are key-value pairs with values of any type, including objects and lists, but that are not indexed. Use metadata to record data you want to store in the trace but don’t need to use for searching traces.
INCORRECT: “Filter expressions” is incorrect. You can use filter expressions to find traces related to specific paths or users.
Question
A developer has deployed an application on an Amazon EC2 instance in a private subnet within a VPC. The subnet does not have Internet connectivity. The developer would like to write application logs to an Amazon S3 bucket. What MUST be configured to enable connectivity?
1: An IAM role must be added to the instance that has permissions to write to
the S3 bucket
2: A bucket policy needs to be added specifying the principles that are allowed to write data to the bucket
3: A VPN should be established to enable private connectivity to S3 4: A VPC endpoint should be provisioned for S3
Answer: 4
Explanation:
Please note that the question specifically asks how to enable connectivity so
this is not about permissions. When using a private subnet with no Internet connectivity there are only two options available for connecting to Amazon S3 (which remember, is a service with a public endpoint, it’s not in your VPC).
The first option is to enable Internet connectivity through either a NAT Gateway or a NAT Instance. However, there is no answer offering either of these as a solution. The other option is to enable a VPC endpoint for S3.
The specific type of VPC endpoint to S3 is a Gateway Endpoint. EC2 instances running in private subnets of a VPC can use the endpoint to enable controlled access to S3 buckets, objects, and API functions that are in the
same region as the VPC. You can then use an S3 bucket policy to indicate which VPCs and which VPC Endpoints have access to your S3 buckets.
In the following diagram, instances in subnet 2 can access Amazon S3 through the gateway endpoint.
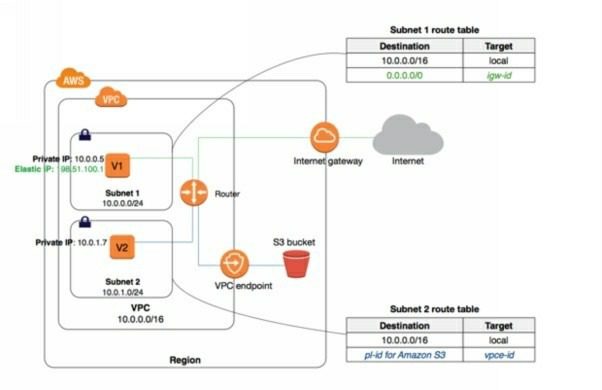
Therefore, the only answer that presents a solution to this challenge is to provision a VPC endpoint for S3.
CORRECT: “A VPC endpoint should be provisioned for S3” is the correct answer.
INCORRECT: “An IAM role must be added to the instance that has permissions to write to the S3 bucket” is incorrect. You do need to do this, but the question is asking about connectivity, not permissions.
INCORRECT: “A bucket policy needs to be added specifying the principles that are allowed to write data to the bucket” is incorrect. You may choose to use a bucket policy to enable permissions but the question is asking about connectivity, not permissions.
INCORRECT: “A VPN should be established to enable private connectivity to S3” is incorrect. You can create a VPN to establish an encrypted tunnel into a VPC from a location outside of AWS. However, you cannot create a VPN connection from a subnet within a VPC to Amazon S3.
Question
A Developer wants to encrypt new objects that are being uploaded to an Amazon S3 bucket by an application. There must be an audit trail of who has used the key during this process. There should be no change to the performance of the application. Which type of encryption meets these requirements?
1: Server-side encryption using S3-managed keys
2: Server-side encryption with AWS KMS-managed keys
3: Client-side encryption with a client-side symmetric master key 4: Client-side encryption with AWS KMS-managed keys
Answer: 2
Explanation:
Server-Side Encryption with Customer Master Keys (CMKs) Stored in AWS Key Management Service (SSE-KMS) is similar to SSE-S3, but with some additional benefits and charges for using this service. There are separate permissions for the use of a CMK that provides added protection against unauthorized access of your objects in Amazon S3. SSE-KMS also provides you with an audit trail that shows when your CMK was used and by whom.
Therefore, the key to answering this question correctly is understanding that you do not get an audit trail of key usage when using S3-managed keys. You can still track API usage if you’re using S3-managed keys, but not key usage. For this solution we need to use server-side encryption and AWS KMS- managed keys.
CORRECT: “Server-side encryption with AWS KMS-managed keys” is the correct answer.
INCORRECT: “Server-side encryption using S3-managed keys” is incorrect as S3-managed keys will not provide an audit trail of key usage as described above.
INCORRECT: “Client-side encryption with a client-side symmetric master key” is incorrect as server-side encryption should be used with a KMS- managed key so we get the audit trail of key usage.
INCORRECT: “Client-side encryption with AWS KMS-managed keys” is incorrect as the encryption should take place server-side so we do not impose any additional processing on the application that may affect performance.
Question
A serverless application uses an Amazon API Gateway and AWS Lambda. The application processes data submitted in a form by users of the application and certain data must be stored and available to subsequent function calls. What is the BEST solution for storing this data?
1: Store the data in an Amazon Kinesis Data Stream 2: Store the data in the /tmp directory
3: Store the data in an Amazon DynamoDB table 4: Store the data in an Amazon SQS queue
Answer: 3
Explanation:
AWS Lambda is a stateless compute service and so you cannot store session data in AWS Lambda itself. You can store a limited amount of information (up to 512 MB) in the /tmp directory. This information is preserved if the function is reused (i.e. the execution context is reused). However, it is not guaranteed that the execution context will be reused so the data could be destroyed.
The /tmp should only be used for data that can be regenerated or for operations that require a local filesystem, but not as a permanent storage solution. It is ideal for setting up database connections that will be needed across invocations of the function as the connection is made once and preserved across invocations.
Amazon DynamoDB is a good solution for this scenario as it is a low-latency NoSQL database that is often used for storing session state data. Amazon S3 would also be a good fit for this scenario but is not offered as an option.
With both Amazon DynamoDB and Amazon S3 you can store data long-term and it is available for multiple invocations of your function as well as being available from multiple invocations simultaneously.
CORRECT: “Store the data in an Amazon DynamoDB table” is the correct answer.
INCORRECT: “Store the data in an Amazon Kinesis Data Stream” is incorrect as this service is used for streaming data. It is not used for session-store use cases.
INCORRECT: “Store the data in the /tmp directory” is incorrect as any data stored in the /tmp may not be available for subsequent calls to your function. The /tmp directory content remains when the execution context is frozen, providing transient cache that can be used for multiple invocations. However, it is not guaranteed that the execution context will be reused so the data could be lost.
INCORRECT: “Store the data in an Amazon SQS queue” is incorrect as a message queue is not used for long-term storage of data.
Question
A Development team need to push an update to an application that is running on AWS Elastic Beanstalk. The business SLA states that the application must maintain full performance capabilities during updates whilst minimizing cost. Which Elastic Beanstalk deployment policy should the development team select?
1: Immutable
2: Rolling
3: All at once
4: Rolling with additional batch
Answer: 4
Explanation:
AWS Elastic Beanstalk provides several options for how deployments are
processed, including deployment policies (All at once, Rolling, Rolling with additional batch, and Immutable) and options that let you configure batch size and health check behavior during deployments. For this scenario we need to ensure we do not reduce the capacity of the application but we also need to minimize cost.
The Rolling with additional batch deployment policy does require extra cost but the extra cost is the size of a batch of instances, therefore you can reduce cost by reducing the batch size. The Immutable deployment policy requires a total deployment of new instances – i.e. if you have 4 instances this will double to 8 instances.
Therefore, the best deployment policy to use for this scenario is the Rolling with additional batch.
CORRECT: “Rolling with additional batch” is the correct answer. INCORRECT: “Immutable” is incorrect as this would require a higher cost as you need a total deployment of new instances.
INCORRECT: “Rolling” is incorrect as this will result in a reduction in capacity which will affect performance.
INCORRECT: “All at once” is incorrect as this results in a total reduction in capacity, i.e. your entire application is taken down at once while the application update is installed.
Question
An organization developed an application that uses a set of APIs that are being served through Amazon API Gateway. The API calls must be authenticated based on OpenID identity providers such as Amazon, Google, or Facebook. The APIs should allow access based on a custom authorization model. Which is the simplest and MOST secure design to use to build an authentication and authorization model for the APIs?
1: Use Amazon ElastiCache to store user credentials and pass them to the APIs for authentication and authorization
2: Use Amazon DynamoDB to store user credentials and have the application retrieve temporary credentials from AWS STS. Make API calls by passing user credentials to the APIs for authentication and authorization
3: Use Amazon Cognito user pools and a custom authorizer to authenticate and authorize users based on JSON Web Tokens
4: Build an OpenID token broker with Amazon and Facebook. Users will authenticate with these identify providers and pass the JSON Web Token to the API to authenticate each API call
Answer: 3
Explanation:
With Amazon Cognito User Pools your app users can sign in either directly through a user pool or federate through a third-party identity provider (IdP). The user pool manages the overhead of handling the tokens that are returned from social sign-in through Facebook, Google, Amazon, and Apple, and from OpenID Connect (OIDC) and SAML IdPs.
After successful authentication, Amazon Cognito returns user pool tokens to your app. You can use the tokens to grant your users access to your own server-side resources, or to the Amazon API Gateway. Or, you can exchange them for AWS credentials to access other AWS services.
The ID token is a JSON Web Token (JWT) that contains claims about the identity of the authenticated user such as name, email, and phone_number. You can use this identity information inside your application. The ID token can also be used to authenticate users against your resource servers or server applications.
CORRECT: “Use Amazon Cognito user pools and a custom authorizer to authenticate and authorize users based on JSON Web Tokens” is the correct answer.
INCORRECT: “Use Amazon ElastiCache to store user credentials and pass them to the APIs for authentication and authorization” is incorrect. This option does not provide a solution for authenticating based on Open ID providers and is not secure as there is no mechanism mentioned for ensuring the secrecy of the credentials.
INCORRECT: “Use Amazon DynamoDB to store user credentials and have the application retrieve temporary credentials from AWS STS. Make API calls by passing user credentials to the APIs for authentication and authorization” is incorrect. This option also does not solve the requirement of integrating with Open ID providers and also suffers from the same security concerns as the option above.
INCORRECT: “Build an OpenID token broker with Amazon and Facebook. Users will authenticate with these identify providers and pass the JSON Web Token to the API to authenticate each API call” is incorrect. This may be a workable and secure solution however it is definitely not the simplest as it would require significant custom development.
Question
An AWS Lambda function has been packaged for deployment to multiple environments including development, test, and production. The Lambda function uses an Amazon RDS MySQL database for storing data. Each environment has a different RDS MySQL database. How can a Developer configure the Lambda function package to ensure the correct database connection string is used for each environment?
1: Use a separate function for development and production 2: Include the resources in the function code
3: Use environment variables for the database connection strings 4: Use layers for storing the database connection strings
Answer: 3
Explanation:
You can use environment variables to store secrets securely and adjust your function’s behavior without updating code. An environment variable is a pair of strings that are stored in a function’s version-specific configuration.
Use environment variables to pass environment-specific settings to your code. For example, you can have two functions with the same code but different configuration. One function connects to a test database, and the other connects to a production database.
In this situation, you use environment variables to tell the function the hostname and other connection details for the database. You might also set an environment variable to configure your test environment to use more verbose logging or more detailed tracing.
You set environment variables on the unpublished version of your function by specifying a key and value. When you publish a version, the environment variables are locked for that version along with other version-specific configuration.
It is possible to create separate versions of a function with different environment variables referencing the relevant database connection strings. Aliases can then be used to differentiate the environments and be used for connecting to the functions.
Therefore, using environment variables is the best way to ensure the environment-specific database connection strings are available in a single deployment package.
CORRECT: “Use environment variables for the database connection strings” is the correct answer.
INCORRECT: “Use a separate function for development and production” is incorrect as there’s a single deployment package that must contain the connection strings for multiple environments. Therefore, using environment variables is necessary.
INCORRECT: “Include the resources in the function code” is incorrect. It would not be secure to include the database connection strings in the function code. With environment variables the password string can be encrypted using
KMS which is much more secure.
INCORRECT: “Use layers for storing the database connection strings” is incorrect. Layers are used for adding external libraries to your functions.
Question
An application is being deployed on an Amazon EC2 instance running Linux. The EC2 instance will need to manage other AWS services. How can the EC2 instance be configured to make API calls to AWS service securely?
1: Run the “aws configure” AWS CLI command and specify the access key ID and secret access key
2: Create an AWS IAM Role, attach a policy with the necessary privileges and attach the role to the instance’s instance profile
3: Store a users’ console login credentials in the application code so the application can call AWS STS and gain temporary security credentials
4: Store the access key ID and secret access key as encrypted AWS Lambda environment variables and invoke Lambda for each API call
Answer: 2
Explanation:
Applications must sign their API requests with AWS credentials. Therefore, if you are an application developer, you need a strategy for managing credentials for your applications that run on EC2 instances. For example, you can securely distribute your AWS credentials to the instances, enabling the applications on those instances to use your credentials to sign requests, while protecting your credentials from other users.
However, it’s challenging to securely distribute credentials to each instance, especially those that AWS creates on your behalf, such as Spot Instances or instances in Auto Scaling groups. You must also be able to update the credentials on each instance when you rotate your AWS credentials.
IAM roles are designed so that your applications can securely make API requests from your instances, without requiring you to manage the security credentials that the applications use.
Instead of creating and distributing your AWS credentials, you can delegate permission to make API requests using IAM roles as follows:
Create an IAM role.
Define which accounts or AWS services can assume the role. Define which API actions and resources the application can use after assuming the role.
Specify the role when you launch your instance or attach the role to an existing instance.
Have the application retrieve a set of temporary credentials and use them.
For example, you can use IAM roles to grant permissions to applications running on your instances that need to use a bucket in Amazon S3. You can specify permissions for IAM roles by creating a policy in JSON format.
These are similar to the policies that you create for IAM users. If you change a role, the change is propagated to all instances.
Therefore, the best solution is to create an AWS IAM Role with the necessary privileges (through an IAM policy) and attach the role to the instance’s instance profile.
CORRECT: “Create an AWS IAM Role, attach a policy with the necessary privileges and attach the role to the instance’s instance profile” is the correct answer.
INCORRECT: “Run the “aws configure” AWS CLI command and specify the access key ID and secret access key” is incorrect as this in insecure as the access key ID and secret access key are stored in plaintext on the instance’s local disk.
INCORRECT: “Store a users’ console login credentials in the application code so the application can call AWS STS and gain temporary security credentials” is incorrect. This is a nonsense solution that would not work for multiple reasons. Firstly, the user console login credentials and not used for API access; secondly the STS service will not accept user login credentials and return temporary access credentials.
INCORRECT: “Store the access key ID and secret access key as encrypted AWS Lambda environment variables and invoke Lambda for each API call” is incorrect. You can encrypt Lambda variables with KMS keys; however, this is not an ideal solution as you will still need to decrypt the keys through the Lambda code and then pass them to the EC2 instance. There could be security risks in this process. This is generally a poor use case for Lambda and IAM Roles are a far superior way of providing the necessary access.
Question
A Developer is building an application that will store data relating to financial transactions in multiple DynamoDB tables. The Developer needs to ensure the transactions provide atomicity, isolation, and durability (ACID) and that changes are committed following an all-or nothing paradigm. What write API should be used for the DynamoDB table?
1: Standard
2: Strongly consistent
3: Transactional
4: Eventually consistent
Answer: 3
Explanation:
Amazon DynamoDB transactions simplify the developer experience of making coordinated, all-or-nothing changes to multiple items both within and across tables. Transactions provide atomicity, consistency, isolation, and durability (ACID) in DynamoDB, helping you to maintain data correctness in your applications.
You can use the DynamoDB transactional read and write APIs to manage complex business workflows that require adding, updating, or deleting multiple items as a single, all-or-nothing operation. For example, a video game developer can ensure that players’ profiles are updated correctly when they exchange items in a game or make in-game purchases.
With the transaction write API, you can group multiple Put, Update, Delete, and ConditionCheck actions. You can then submit the actions as a single TransactWriteItems operation that either succeeds or fails as a unit. The same is true for multiple Get actions, which you can group and submit as a single TransactGetItems operation.
There is no additional cost to enable transactions for your DynamoDB tables. You pay only for the reads or writes that are part of your transaction.
DynamoDB performs two underlying reads or writes of every item in the transaction: one to prepare the transaction and one to commit the transaction. These two underlying read/write operations are visible in your Amazon CloudWatch metrics.
CORRECT: “Transactional” is the correct answer.
INCORRECT: “Standard” is incorrect as this will not provide the ACID / all-or nothing transactional writes that are required for this solution.
INCORRECT: “Strongly consistent” is incorrect as this applies to reads only, not writes.
INCORRECT: “Eventually consistent” is incorrect as this applies to reads only, not writes.
Question
A Developer will be launching several Docker containers on a new Amazon ECS cluster using the EC2 Launch Type. The containers will all run a web service on port 80. What is the EASIEST way the Developer can configure the task definition to ensure the web services run correctly and there are no port conflicts on the host instances?
1: Specify port 80 for the container port and a unique port number for the host port
2: Specify a unique port number for the container port and port 80 for the host port
3: Specify port 80 for the container port and port 0 for the host port 4: Leave both the container port and host port configuration blank
Answer: 3
Explanation:
Port mappings allow containers to access ports on the host container instance
to send or receive traffic. Port mappings are specified as part of the container definition. The container port is the port number on the container that is bound to the user-specified or automatically assigned host port. The host port is the port number on the container instance to reserve for your container.
As we cannot have multiple services bound to the same host port, we need to ensure that each container port mapping uses a different host port. The easiest way to do this is to set the host port number to 0 and ECS will automatically assign an available port. We also need to assign port 80 to the container port so that the web service is able to run.
CORRECT: “Specify port 80 for the container port and port 0 for the host port” is the correct answer.
INCORRECT: “Specify port 80 for the container port and a unique port number for the host port” is incorrect as this is more difficult to manage as
you have to manually assign the port number.
INCORRECT: “Specify a unique port number for the container port and port 80 for the host port” is incorrect as the web service on the container needs to run on pot 80 and you can only bind one container to port 80 on the host so this would not allow more than one container to work.
INCORRECT: “Leave both the container port and host port configuration blank” is incorrect as this would mean that ECS would dynamically assign both the container and host port. As the web service must run on port 80 this would not work correctly.
Question
A Developer is designing a fault-tolerant application that will use Amazon EC2 instances and an Elastic Load Balancer. The Developer needs to ensure that if an EC2 instance fails session data is not lost. How can this be achieved?
1: Enable Sticky Sessions on the Elastic Load Balancer
2: Use an EC2 Auto Scaling group to automatically launch new instances 3: Use Amazon DynamoDB to perform scalable session handling
4: Use Amazon SQS to save session data
Answer: 3
Explanation:
For this scenario the key requirement is to ensure the data is not lost.
Therefore, the data must be stored in a durable data store outside of the EC2 instances. Amazon DynamoDB is a suitable solution for storing session data. DynamoDB has a session handling capability for multiple languages as in the below example for PHP:
“The DynamoDB Session Handler is a custom session handler for PHP that allows developers to use Amazon DynamoDB as a session store. Using DynamoDB for session storage alleviates issues that occur with session handling in a distributed web application by moving sessions off of the local file system and into a shared location. DynamoDB is fast, scalable, easy to setup, and handles replication of your data automatically.”
Therefore, the best answer is to use DynamoDB to store the session data. CORRECT: “Use Amazon DynamoDB to perform scalable session handling” is the correct answer.
INCORRECT: “Enable Sticky Sessions on the Elastic Load Balancer” is incorrect. Sticky sessions attempts to direct a user that has reconnected to the application to the same EC2 instance that they connected to previously.
However, this does not ensure that the session data is going to be available. INCORRECT: “Use an EC2 Auto Scaling group to automatically launch new instances” is incorrect as this does not provide a solution for storing the session data.
INCORRECT: “Use Amazon SQS to save session data” is incorrect as Amazon SQS is not suitable for storing session data.
Question
A CloudFormation stack needs to be deployed in several regions and requires a different Amazon Machine Image (AMI) in each region.
Which AWS CloudFormation template key can be used to specify the correct AMI for each region?
1: Outputs
2: Parameters
3: Resources
4: Mappings
Answer: 4
Explanation:
The optional Mappings section matches a key to a corresponding set of
named values. For example, if you want to set values based on a region, you can create a mapping that uses the region name as a key and contains the values you want to specify for each specific region. You use the Fn::FindInMap intrinsic function to retrieve values in a map.
The following example shows a Mappings section with a map RegionMap, which contains five keys that map to name-value pairs containing single string values. The keys are region names. Each name-value pair is the AMI ID for the HVM64 AMI in the region represented by the key.
CORRECT: “Mappings” is the correct answer.
INCORRECT: “Outputs” is incorrect. The optional Outputs section declares output values that you can import into other stacks (to create cross-stack references), return in response (to describe stack calls), or view on the AWS CloudFormation console.
INCORRECT: “Parameters” is incorrect. Parameters enable you to input custom values to your template each time you create or update a stack.
INCORRECT: “Resources” is incorrect. The required Resources section declares the AWS resources that you want to include in the stack, such as an Amazon EC2 instance or an Amazon S3 bucket.
Question
A company has an application that logs all information to Amazon S3. Whenever there is a new log file, an AWS Lambda function is invoked to process the log files. The code works, gathering all of the necessary information. However, when checking the Lambda function logs, duplicate entries with the same request ID are found. What is the BEST explanation for the duplicate entries?
1: The S3 bucket name was specified incorrectly
2: The Lambda function failed, and the Lambda service retried the invocation with a delay
3: There was an S3 outage, which caused duplicate entries of the same log file
4: The application stopped intermittently and then resumed
Answer: 2
Explanation:
From the AWS documentation:
“When an error occurs, your function may be invoked multiple times. Retry behavior varies by error type, client, event source, and invocation type. For example, if you invoke a function asynchronously and it returns an error, Lambda executes the function up to two more times. For more information, see Retry Behavior.
For asynchronous invocation, Lambda adds events to a queue before sending them to your function. If your function does not have enough capacity to keep up with the queue, events may be lost. Occasionally, your function may receive the same event multiple times, even if no error occurs. To retain events that were not processed, configure your function with a dead-letter queue.”
Therefore, the most likely explanation is that the function failed, and Lambda retried the invocation.
CORRECT: “The Lambda function failed, and the Lambda service retried the invocation with a delay” is the correct answer.
INCORRECT: “The S3 bucket name was specified incorrectly” is incorrect. If this was the case all attempts would fail but this is not the case.
INCORRECT: “There was an S3 outage, which caused duplicate entries of the same log file” is incorrect. There cannot be duplicate log files in Amazon S3 as every object must be unique within a bucket. Therefore, if the same log file was uploaded twice it would just overwrite the previous version of the file. Also, if a separate request was made to Lambda it would have a different request ID.
INCORRECT: “The application stopped intermittently and then resumed” is incorrect. The issue is duplicate entries of the same request ID.
Question
An AWS Lambda function authenticates to an external web site using a regularly rotated user name and password. The credentials need to be stored securely and must not be stored in the function code. What combination of AWS services can be used to achieve this requirement? (Select TWO)
1: AWS Certificate Manager (ACM)
2: AWS Systems Manager Parameter Store 3: AWS Key Management Store (KMS)
4: AWS Artifact
5: Amazon GuardDuty
Answer: 2,3
Explanation:
With AWS Systems Manager Parameter Store, you can create secure string parameters, which are parameters that have a plaintext parameter name and an encrypted parameter value. Parameter Store uses AWS KMS to encrypt and decrypt the parameter values of secure string parameters.
With Parameter Store you can create, store, and manage data as parameters with values. You can create a parameter in Parameter Store and use it in multiple applications and services subject to policies and permissions that you design. When you need to change a parameter value, you change one instance, rather than managing error-prone changes to numerous sources.
Parameter Store supports a hierarchical structure for parameter names, so you can qualify a parameter for specific uses.
To manage sensitive data, you can create secure string parameters. Parameter Store uses AWS KMS customer master keys (CMKs) to encrypt the parameter values of secure string parameters when you create or change them. It also uses CMKs to decrypt the parameter values when you access them. You can use the AWS managed CMK that Parameter Store creates for your account or specify your own customer managed CMK.
Therefore, you can use a combination of AWS Systems Manager Parameter Store and AWS Key Management Store to store the credentials securely.
These keys can be then be referenced in the Lambda function code or through environment variables.
NOTE: Systems Manager Parameter Store does not natively perform rotation of credentials so this must be done in the application. AWS Secrets Manager does perform credential rotation however it is not an answer option for this question.
CORRECT: “AWS Systems Manager Parameter Store” is a correct answer. CORRECT: “AWS Key Management Store (KMS)” is also a correct answer.
INCORRECT: “AWS Certificate Manager (ACM)” is incorrect as this service is used to issue SSL/TLS certificates not encryption keys.
INCORRECT: “AWS Artifact” is incorrect as this is a service to view compliance information about the AWS platform
INCORRECT: “Amazon GuardDuty” is incorrect. Amazon GuardDuty is a threat detection service that continuously monitors for malicious activity and unauthorized behavior to protect your AWS accounts and workloads.
Question
A Development team would use a GitHub repository and would like to migrate their application code to AWS CodeCommit. What needs to be created before they can migrate a cloned repository to CodeCommit over HTTPS?
1: A GitHub secure authentication token 2: A public and private SSH key file
3: A set of Git credentials generated with IAM
4: An Amazon EC2 IAM role with CodeCommit permissions
Answer: 3
Explanation:
AWS CodeCommit is a managed version control service that hosts private Git repositories in the AWS cloud. To use CodeCommit, you configure your Git client to communicate with CodeCommit repositories. As part of this configuration, you provide IAM credentials that CodeCommit can use to authenticate you. IAM supports CodeCommit with three types of credentials:
Git credentials, an IAM -generated user name and password pair you can use to communicate with CodeCommit repositories over HTTPS.
SSH keys, a locally generated public-private key pair that you can associate with your IAM user to communicate with CodeCommit repositories over SSH.
AWS access keys, which you can use with the credential helper included with the AWS CLI to communicate with CodeCommit repositories over HTTPS.
In this scenario the Development team need to connect to CodeCommit using HTTPS so they need either AWS access keys to use the AWS CLI or Git credentials generated by IAM. Access keys are not offered as an answer choice so the best answer is that they need to create a set of Git credentials generated with IAM
CORRECT: “A set of Git credentials generated with IAM” is the correct answer.
INCORRECT: “A GitHub secure authentication token” is incorrect as they need to authenticate to AWS CodeCommit, not GitHub (they have already accessed and cloned the repository).
INCORRECT: “A public and private SSH key file” is incorrect as these are used to communicate with CodeCommit repositories using SSH, not HTTPS. INCORRECT: “An Amazon EC2 IAM role with CodeCommit permissions” is incorrect as you need the Git credentials generated through IAM to connect to CodeCommit.
Question
A company has a large Amazon DynamoDB table which they scan periodically so they can analyze several attributes. The scans are
consuming a lot of provisioned throughput. What technique can a Developer use to minimize the impact of the scan on the table’s provisioned throughput?
1: Set a smaller page size for the scan 2: Use parallel scans
3: Define a range key on the table
4: Prewarm the table by updating all items
Answer: 1
Explanation:
In general, Scan operations are less efficient than other operations in
DynamoDB. A Scan operation always scans the entire table or secondary index. It then filters out values to provide the result you want, essentially adding the extra step of removing data from the result set.
If possible, you should avoid using a Scan operation on a large table or index with a filter that removes many results. Also, as a table or index grows,
the Scan operation slows. The Scan operation examines every item for the requested values and can use up the provisioned throughput for a large table or index in a single operation.
Instead of using a large Scan operation, you can use the following techniques to minimize the impact of a scan on a table’s provisioned throughput.
Reduce page size because a Scan operation reads an entire page (by default, 1 MB), you can reduce the impact of the scan operation by setting a smaller page size.
The Scan operation provides a Limit parameter that you can use to set the page size for your request. Each Query or Scan request that has a smaller page size uses fewer read operations and creates a “pause” between each request.
Isolate scan operations DynamoDB is designed for easy scalability. As a result, an application can create tables for distinct purposes, possibly even duplicating content across several tables. You want to perform scans on a table that is not taking “mission-critical” traffic. Some applications handle this load by rotating traffic hourly between two tables—one for critical traffic, and one for
bookkeeping. Other applications can do this by performing every write on two tables: a “mission-critical” table, and a “shadow” table.
Therefore, the best option to reduce the impact of the scan on the table’s provisioned throughput is to set smaller page size for the scan.
CORRECT: “Set a smaller page size for the scan” is the correct answer.
INCORRECT: “Use parallel scans” is incorrect as this will return results faster but place more burden on the table’s provisioned throughput.
INCORRECT: “Define a range key on the table” is incorrect. A range key is a composite key that includes the hash key and another attribute. This is of limited use in this scenario as the table is being scanned to analyze multiple attributes.
INCORRECT: “Prewarm the table by updating all items” is incorrect as updating all items would incur significant costs in terms of provisioned throughput and would not be advantageous.
Question
A Developer is deploying an application in a microservices architecture on Amazon ECS. The Developer needs to choose the best task placement strategy to MINIMIZE the number of instances that are used. Which task placement strategy should be used?
1: spread
2: random
3: binpack
4: weighted
Answer: 3
Explanation:
A task placement strategy is an algorithm for selecting instances for task placement or tasks for termination. Task placement strategies can be specified when either running a task or creating a new service.
Amazon ECS supports the following task placement strategies:
binpack – Place tasks based on the least available amount of CPU or memory. This minimizes the number of instances in use.
random – Place tasks randomly.
spread – Place tasks evenly based on the specified value. Accepted values
are instanceId (or host, which has the same effect), or any platform or custom attribute that is applied to a container instance, such
as attribute:ecs.availability-zone. Service tasks are spread based on the tasks from that service. Standalone tasks are spread based on the tasks from the same task group.
The binpack task placement strategy is the most suitable for this scenario as it minimizes the number of instances used which is a requirement for this solution.
CORRECT: “binpack” is the correct answer.
INCORRECT: “random” is incorrect as this would assign tasks randomly to EC2 instances which would not result in minimizing the number of instances used.
INCORRECT: “spread” is incorrect as this would spread the tasks based on a specified value. This is not used for minimizing the number of instances used.
INCORRECT: “weighted” is incorrect as this is not an ECS task placement strategy. Weighted is associated with Amazon Route 53 routing policies.
Question
A company has created a set of APIs using Amazon API Gateway and exposed them to partner companies. The APIs have caching enabled for all stages. The partners require a method of invalidating the cache that they can build into their applications. What can the partners use to invalidate the API cache?
1: They can pass the HTTP header Cache-Control: max-age=0
2: They can use the query string parameter INVALIDATE_CACHE 3: They must wait for the TTL to expire
4: They can invoke an AWS API endpoint which invalidates the cache
Answer: 1
Explanation:
You can enable API caching in Amazon API Gateway to cache your endpoint’s responses. With caching, you can reduce the number of calls made to your endpoint and also improve the latency of requests to your API.
When you enable caching for a stage, API Gateway caches responses from your endpoint for a specified time-to-live (TTL) period, in seconds. API
Gateway then responds to the request by looking up the endpoint response from the cache instead of making a request to your endpoint. The default TTL value for API caching is 300 seconds. The maximum TTL value is 3600 seconds. TTL=0 means caching is disabled.
A client of your API can invalidate an existing cache entry and reload it from the integration endpoint for individual requests. The client must send a request that contains the Cache-Control: max-age=0 header.
The client receives the response directly from the integration endpoint instead of the cache, provided that the client is authorized to do so. This replaces the existing cache entry with the new response, which is fetched from the integration endpoint. To grant permission for a client, attach a policy of the following format to an IAM execution role for the user.

This policy allows the API Gateway execution service to invalidate the cache for requests on the specified resource (or resources).
Therefore, as described above the solution is to get the partners to pass the HTTP header Cache-Control: max-age=0.
CORRECT: “They can pass the HTTP header Cache-Control: max-age=0” is the correct answer.
INCORRECT: “They can use the query string parameter INVALIDATE_CACHE” is incorrect. This is not a valid method of invalidating the cache with API Gateway.
INCORRECT: “They must wait for the TTL to expire” is incorrect as this is not true, you do not need to wait as you can pass the HTTP header Cache- Control: max-age=0 whenever you need to in order to invalidate the cache.
INCORRECT: “They can invoke an AWS API endpoint which invalidates the cache” is incorrect. This is not a valid method of invalidating the cache with API Gateway.
Question
A Developer is deploying an AWS Lambda update using AWS CodeDeploy. In the appspec.yml file, which of the following is a valid structure for the order of hooks that should be specified?
1: BeforeInstall > AfterInstall > AfterAllowTestTraffic > BeforeAllowTraffic > AfterAllowTraffic
2: BeforeInstall > AfterInstall > ApplicationStart > ValidateService
3: BeforeAllowTraffic > AfterAllowTraffic
4: BeforeBlockTraffic > AfterBlockTraffic > BeforeAllowTraffic > AfterAllowTraffic
Answer: 3
Explanation:
The content in the ‘hooks’ section of the AppSpec file varies, depending on the compute platform for your deployment. The ‘hooks’ section for an EC2/On-Premises deployment contains mappings that link deployment lifecycle event hooks to one or more scripts.
The ‘hooks’ section for a Lambda or an Amazon ECS deployment specifies Lambda validation functions to run during a deployment lifecycle event. If an event hook is not present, no operation is executed for that event. This section is required only if you are running scripts or Lambda validation functions as part of the deployment.
CORRECT: “BeforeAllowTraffic > AfterAllowTraffic” is the correct answer.
INCORRECT: “BeforeInstall > AfterInstall > ApplicationStart > ValidateService” is incorrect as this would be valid for Amazon EC2. INCORRECT: “BeforeInstall > AfterInstall > AfterAllowTestTraffic > BeforeAllowTraffic > AfterAllowTraffic” is incorrect as this would be valid for Amazon ECS.
INCORRECT: “BeforeBlockTraffic > AfterBlockTraffic > BeforeAllowTraffic > AfterAllowTraffic” is incorrect as this is a partial listing of hooks for Amazon EC2 but is incomplete.
Question
A Developer needs to scan a full DynamoDB 50GB table within non-peak hours. About half of the strongly consistent RCUs are typically used during non-peak hours and the scan duration must be minimized. How can the Developer optimize the scan execution time without impacting production workloads?
1: Use sequential scans
2: Use parallel scans while limiting the rate
3: Increase the RCUs during the scan operation
4: Change to eventually consistent RCUs during the scan operation
Answer: 2
Explanation:
Performing a scan on a table consumes a lot of RCUs. A Scan operation always scans the entire table or secondary index. It then filters out values to provide the result you want, essentially adding the extra step of removing data from the result set. To reduce the amount of RCUs used by the scan so it doesn’t affect production workloads whilst minimizing the execution time, there are a couple of recommendations the Developer can follow.
Firstly, the Limit parameter can be used to reduce the page size.
The Scan operation provides a Limit parameter that you can use to set the page size for your request. Each Query or Scan request that has a smaller page size uses fewer read operations and creates a “pause” between each request.
Secondly, the Developer can configure parallel scans. With parallel scans the Developer can maximize usage of the available throughput and have the scans distributed across the table’s partitions.
A parallel scan can be the right choice if the following conditions are met: The table size is 20 GB or larger.
The table’s provisioned read throughput is not being fully used. Sequential Scan operations are too slow.
Therefore, to optimize the scan operation the Developer should use parallel scans while limiting the rate as this will ensure that the scan operation does not affect the performance of production workloads and still have it complete in the minimum time.
CORRECT: “Use parallel scans while limiting the rate” is the correct answer.
INCORRECT: “Use sequential scans” is incorrect as this is slower than parallel scans and the Developer needs to minimize scan execution time. INCORRECT: “Increase the RCUs during the scan operation” is incorrect as the table is only using half of the RCUs during non-peak hours so there are RCUs available. You could increase RCUs and perform the scan faster, but this would be more expensive. The better solution is to use parallel scans with the limit parameter.
INCORRECT: “Change to eventually consistent RCUs during the scan operation” is incorrect as this does not provide a solution for preventing impact to the production workloads. The limit parameter should be used to ensure the table’s RCUs are not fully used.
Question
A Development team is involved with migrating an on-premises MySQL database to Amazon RDS. The database usage is very read-heavy. The Development team wants re-factor the application code to achieve optimum read performance for queries. How can this objective be met? 1: Add database retries to the code and vertically scale the Amazon RDS database
2: Use Amazon RDS with a multi-AZ deployment
3: Add a connection string to use an Amazon RDS read replica for read queries
4: Add a connection string to use a read replica on an Amazon EC2 instance
Answer: 3
Explanation:
Amazon RDS uses the MariaDB, MySQL, Oracle, and PostgreSQL DB engines’ built-in replication functionality to create a special type of DB instance called a Read Replica from a source DB instance. Updates made to the source DB instance are asynchronously copied to the Read Replica.
You can reduce the load on your source DB instance by routing read queries from your applications to the Read Replica. Using Read Replicas, you can elastically scale out beyond the capacity constraints of a single DB instance for read-heavy database workloads.
A primary Amazon RDS database server allows reads and writes while a Read Replica can be used for running read-only workloads such as BI/reporting. This reduces the load on the primary database.
It is necessary to add logic to your code to direct read traffic to the Read Replica and write traffic to the primary database. Therefore, in this scenario the Development team will need to “Add a connection string to use an Amazon RDS read replica for read queries”.
CORRECT: “Add a connection string to use an Amazon RDS read replica for read queries” is the correct answer.
INCORRECT: “Add database retries to the code and vertically scale the Amazon RDS database” is incorrect as this is not a good way to scale reads as you will likely hit a ceiling at some point in terms of cost or instance type.
Scaling reads can be better implemented with horizontal scaling using a Read Replica.
INCORRECT: “Use Amazon RDS with a multi-AZ deployment” is incorrect as this creates a standby copy of the database in another AZ that can be failed over to in a failure scenario. This is used for DR not (at least not primarily) used for scaling performance. It is possible for certain RDS engines to use a multi-AZ standby as a read replica however the requirements in this solution do not warrant this configuration.
INCORRECT: “Add a connection string to use a read replica on an Amazon EC2 instance” is incorrect as Read Replicas are something you create on Amazon RDS, not on an EC2 instance.
Question
To reduce the cost of API actions performed on an Amazon SQS queue, a Developer has decided to implement long polling. Which of the following modifications should the Developer make to the API actions?
1: Set the ReceiveMessage API with a WaitTimeSeconds of 20
2: Set the SetQueueAttributes API with a DelaySeconds of 20 3: Set the ReceiveMessage API with a VisibilityTimeout of 30
4: Set the SetQueueAttributes with a MessageRetentionPeriod of 60
Answer: 1
Explanation:
The process of consuming messages from a queue depends on whether you use short or long polling. By default, Amazon SQS uses short polling, querying only a subset of its servers (based on a weighted random distribution) to determine whether any messages are available for a response. You can use long polling to reduce your costs while allowing your consumers to receive messages as soon as they arrive in the queue.
When you consume messages from a queue using short polling, Amazon SQS samples a subset of its servers (based on a weighted random distribution) and returns messages from only those servers. Thus, a particular ReceiveMessage request might not return all of your messages.
However, if you have fewer than 1,000 messages in your queue, a subsequent request will return your messages. If you keep consuming from your queues, Amazon SQS samples all of its servers, and you receive all of your messages. When the wait time for the ReceiveMessage API action is greater than 0, long polling is in effect. The maximum long polling wait time is 20 seconds. Long polling helps reduce the cost of using Amazon SQS by eliminating the number of empty responses (when there are no messages available for a ReceiveMessage request) and false empty responses (when messages are available but aren’t included in a response).
Long polling occurs when the WaitTimeSeconds parameter of a ReceiveMessage request is set to a value greater than 0 in one of two ways: The ReceiveMessage call sets WaitTimeSeconds to a value greater than 0.
The ReceiveMessage call doesn’t set WaitTimeSeconds, but the queue attribute ReceiveMessageWaitTimeSeconds is set to a value greater than 0.
Therefore, the Developer should set the ReceiveMessage API with a WaitTimeSeconds of 20.
CORRECT: “Set the ReceiveMessage API with a WaitTimeSeconds of 20” is the correct answer.
INCORRECT: “Set the SetQueueAttributes API with a DelaySeconds of 20” is incorrect as this would be used to configure a delay queue where the delivery of messages in the queue is delayed.
INCORRECT: “Set the ReceiveMessage API with a VisibilityTimeout of 30” is incorrect as this would configure the visibility timeout which is the length of time a message that has been received is invisible.
INCORRECT: “Set the SetQueueAttributes with a MessageRetentionPeriod of 60” is incorrect as this would configure how long messages are retained in the queue.
Question
A company is deploying an Amazon Kinesis Data Streams application that will collect streaming data from a gaming application. Consumers will run on Amazon EC2 instances. In this architecture, what can be deployed on consumers to act as an intermediary between the record processing logic and Kinesis Data Streams and instantiate a record processor for each shard?
1: Amazon Kinesis API 2: AWS CLI
3: Amazon Kinesis CLI
4: Amazon Kinesis Client Library (KCL)
Answer: 4
Explanation:
The Kinesis Client Library (KCL) helps you consume and process data from a Kinesis data stream. This type of application is also referred to as a consumer. The KCL takes care of many of the complex tasks associated with distributed computing, such as load balancing across multiple instances, responding to instance failures, checkpointing processed records, and reacting to resharding. The KCL enables you to focus on writing record- processing logic.
The KCL is different from the Kinesis Data Streams API that is available in the AWS SDKs. The Kinesis Data Streams API helps you manage many aspects of Kinesis Data Streams (including creating streams, resharding, and putting and getting records). The KCL provides a layer of abstraction specifically for processing data in a consumer role.
Therefore, the correct answer is to use the Kinesis Client Library.
CORRECT: “Amazon Kinesis Client Library (KCL)” is the correct answer.
INCORRECT: “Amazon Kinesis API” is incorrect. You can work with Kinesis Data Streams directly from your consumers using the API but this is does not deploy an intermediary component as required.
INCORRECT: “AWS CLI” is incorrect. The AWS CLI can be used to work directly with the Kinesis API but this does not deploy an intermediary component as required.
INCORRECT: “Amazon Kinesis CLI” is incorrect as this does not exist. The AWS CLI has commands for working with Kinesis.
Question
A serverless application uses an AWS Lambda function to process Amazon S3 events. The Lambda function executes 20 times per second and takes 20 seconds to complete each execution. How many concurrent executions will the Lambda function require?
1: 5
2: 400
3: 40
4: 20
Answer: 2
Explanation:
Concurrency is the number of requests that your function is serving at any
given time. When your function is invoked, Lambda allocates an instance of it to process the event. When the function code finishes running, it can handle another request. If the function is invoked again while a request is still being processed, another instance is allocated, which increases the function’s concurrency.
To calculate the concurrency requirements for the Lambda function simply multiply the number of executions per second (20) by the time it takes to complete the execution (20).
Therefore, for this scenario the calculation is 20 x 20 = 400.
CORRECT: “400” is the correct answer.
INCORRECT: “5” is incorrect. Please use the formula above to calculate concurrency requirements.
INCORRECT: “40” is incorrect. Please use the formula above to calculate concurrency requirements.
INCORRECT: “20” is incorrect. Please use the formula above to calculate concurrency requirements.
Question
A Developer needs to be notified by email when a new object is uploaded to a specific Amazon S3 bucket. What is the EASIEST way for the Developer to enable these notifications?
1: Add an event to the S3 bucket for PUT and POST events and use an Amazon SNS Topic
2: Add an event to the S3 bucket for PUT and POST events and use an Amazon SQS queue
3: Add an event to the S3 bucket for PUT and POST events and use an AWS Lambda function
4: Add an event to the S3 bucket for all object create events and use AWS Step Functions
Answer: 1
Explanation:
The Amazon S3 notification feature enables you to receive notifications when certain events happen in your bucket. To enable notifications, you must first add a notification configuration that identifies the events you want Amazon S3 to publish and the destinations where you want Amazon S3 to send the notifications. You store this configuration in the notification subresource that is associated with a bucket.
Amazon Simple Notification Service (SNS) is a service that allows you to send notifications from the cloud in a publisher / subscriber model. It supports multiple transport protocols including email.
The easiest option presented is therefore to add an event to the S3 bucket for PUT and POST events and use an Amazon SNS Topic.
CORRECT: “Add an event to the S3 bucket for PUT and POST events and use an Amazon SNS Topic” is the correct answer.
INCORRECT: “Add an event to the S3 bucket for PUT and POST events and use an Amazon SQS queue” is incorrect as SQS is a message queue and is not suitable for when you want to trigger an email notification.
INCORRECT: “Add an event to the S3 bucket for PUT and POST events and use an AWS Lambda function” is incorrect as this would also not be the
best service for triggering an email notification.
INCORRECT: “Add an event to the S3 bucket for all object create events and use AWS Step Functions” is incorrect as this service is involved with the coordination of serverless workflows, it is not used for triggering email notifications.
Question
A Developer is setting up a code update to Amazon ECS using AWS CodeDeploy. The Developer needs to complete the code update quickly. Which of the following deployment types should the Developer use?
1: In-place
2: Canary
3: Blue/green
4: Linear
Answer: 3
Explanation:
CodeDeploy provides two deployment type options – in-place and blue/green. Note that AWS Lambda and Amazon ECS deployments cannot use an in-place deployment type.
The Blue/green deployment type on an Amazon ECS compute platform works like this:
Traffic is shifted from the task set with the original version of an application in an Amazon ECS service to a replacement task set in the same service.
You can set the traffic shifting to linear or canary through the deployment configuration.
The protocol and port of a specified load balancer listener is used to reroute production traffic.
During a deployment, a test listener can be used to serve traffic to the replacement task set while validation tests are run.
CORRECT: “Blue/green” is the correct answer.
INCORRECT: “Canary” is incorrect as this is a traffic shifting option, not a deployment type. Traffic is shifted in two increments.
INCORRECT: “Linear” is incorrect as this is a traffic shifting option, not a deployment type. Traffic is shifted in two increments.
INCORRECT: “In-place” is incorrect as AWS Lambda and Amazon ECS deployments cannot use an in-place deployment type.
Question
Change management procedures at an organization require that a log is kept recording activity within AWS accounts. The activity that must be recorded includes API activity related to creating, modifying or deleting AWS resources. Which AWS service should be used to record this information?
1: Amazon CloudWatch
2: Amazon CloudTrail
3: AWS X-Ray
4: AWS OpsWorks
Answer: 2
Explanation:
AWS CloudTrail is a service that enables governance, compliance, operational auditing, and risk auditing of your AWS account. With CloudTrail, you can log, continuously monitor, and retain account activity related to actions across your AWS infrastructure. CloudTrail provides event history of your AWS account activity, including actions taken through the AWS Management Console, AWS SDKs, command line tools, and other AWS services.
This event history simplifies security analysis, resource change tracking, and troubleshooting. In addition, you can use CloudTrail to detect unusual activity in your AWS accounts. These capabilities help simplify operational analysis and troubleshooting.
Therefore, Amazon CloudTrail is the most suitable service for the requirements in this scenario.
CORRECT: “Amazon CloudTrail” is the correct answer.
INCORRECT: “Amazon CloudWatch” is incorrect as this service is used for performance monitoring, not recording API actions.
INCORRECT: “AWS X-Ray” is incorrect as this is used for tracing application activity for performance and operational statistics.
INCORRECT: “AWS OpsWorks” is incorrect as this is a configuration management service that helps you build and operate highly dynamic applications and propagate changes instantly.
Question
A company is deploying an on-premise application server that will connect to several AWS services. What is the BEST way to provide the application server with permissions to authenticate to AWS services? 1: Create an IAM role with the necessary permissions and assign it to the application server
2: Create an IAM user and generate access keys. Create a credentials file on the application server
3: Create an IAM group with the necessary permissions and add the on- premise application server to the group
4: Create an IAM user and generate a key pair. Use the key pair in API calls to AWS services
Answer: 2
Explanation:
Access keys are long-term credentials for an IAM user or the AWS account root user. You can use access keys to sign programmatic requests to the AWS CLI or AWS API (directly or using the AWS SDK).
Access keys are stored in one of the locations on a client that needs to make authenticated API calls to AWS services:
Linux: ~/.aws/credentials
Windows: %UserProfle%\.aws\credentials
In this scenario the application server is running on-premises. Therefore, you cannot assign an IAM role (which would be the preferable solution for Amazon EC2 instances). In this case it is therefore better to use access keys.
CORRECT: “Create an IAM user and generate access keys. Create a credentials file on the application server” is the correct answer.
INCORRECT: “Create an IAM role with the necessary permissions and assign it to the application server” is incorrect. This is an on-premises server so it is not possible to use an IAM role. If it was an EC2 instance, this would be the preferred (best practice) option.
INCORRECT: “Create an IAM group with the necessary permissions and add the on-premise application server to the group” is incorrect. You cannot add a server to an IAM group. You put IAM users into groups and assign permissions to them using a policy.
INCORRECT: “Create an IAM user and generate a key pair. Use the key pair in API calls to AWS services” is incorrect as key pairs are used for SSH access to Amazon EC2 instances. You cannot use them in API calls to AWS services.
Question
A Developer is creating an application that will run on Amazon EC2 instances. The application will process encrypted files. The files must be decrypted prior to processing. Which of the following steps should be taken to securely decrypt the data? (Select TWO)
1: Pass the encrypted data key to the Decrypt operation
2: Use the encrypted data key to decrypt the data and then remove the encrypted data key from memory as soon as possible
3: Use the plaintext data key to decrypt the data and then remove the plaintext data key from memory as soon as possible
4: Use the plaintext data key to decrypt the data and then remove the encrypted data key from memory as soon as possible
5: Pass the plaintext data key to the Decrypt operation
Answer: 1,3
Explanation:
When you encrypt your data, your data is protected, but you have to protect
your encryption key. One strategy is to encrypt it. Envelope encryption is the practice of encrypting plaintext data with a data key, and then encrypting the data key under another key.
You can even encrypt the data encryption key under another encryption key and encrypt that encryption key under another encryption key. But, eventually, one key must remain in plaintext so you can decrypt the keys and your data. This top-level plaintext key encryption key is known as the master key.
To decrypt your data, pass the encrypted data key to the Decrypt operation. AWS KMS uses your CMK to decrypt the data key and then it returns the plaintext data key. Use the plaintext data key to decrypt your data and then remove the plaintext data key from memory as soon as possible.
CORRECT: “Pass the encrypted data key to the Decrypt operation” is a correct answer.
CORRECT: “Use the plaintext data key to decrypt the data and then remove the plaintext data key from memory as soon as possible” is also a correct answer.
INCORRECT: “Use the encrypted data key to decrypt the data and then remove the encrypted data key from memory as soon as possible” is incorrect as you can only decrypt data with an unencrypted data key.
INCORRECT: “Use the plaintext data key to decrypt the data and then remove the encrypted data key from memory as soon as possible” is incorrect as it’s the plaintext data key that must be removed from memory as it’s a security concern.
INCORRECT: “Pass the plaintext data key to the Decrypt operation” is incorrect as the encrypted data key should be passed to the Decrypt operation.
Question
A Developer needs to launch a serverless static website. The Developer needs to get the website up and running quickly and easily. What should the Developer do?
1: Configure an Amazon S3 bucket as a static website
2: Configure an Amazon EC2 instance with Apache
3: Create an AWS Lambda function with an API Gateway front-end 4: Share an Amazon EFS volume as a static website
Answer: 1
Explanation:
You can use Amazon S3 to host a static website. On a static website, individual webpages include static content. They might also contain client- side scripts.
To host a static website on Amazon S3, you configure an Amazon S3 bucket for website hosting and then upload your website content to the bucket. When you configure a bucket as a static website, you enable static website hosting, set permissions, and add an index document. Depending on your website requirements, you can also configure other options, including redirects, web traffic logging, and custom error documents.
CORRECT: “Configure an Amazon S3 bucket as a static website” is the correct answer.
INCORRECT: “Configure an Amazon EC2 instance with Apache” is incorrect as this is not a serverless solution.
INCORRECT: “Create an AWS Lambda function with an API Gateway front-end” is incorrect as this is not the easiest way to create a static website. Using Amazon S3 would be easier.
INCORRECT: “Share an Amazon EFS volume as a static website” is incorrect as you cannot share an Amazon EFS volume as a static website.
Question
A Developer requires a multi-threaded in-memory cache to place in front of an Amazon RDS database. Which caching solution should the Developer choose?
1: Amazon DynamoDB DAX 2: Amazon ElastiCache Redis
3: Amazon ElastiCache Memcached 4: Amazon RedShift
Answer: 3
Explanation:
Amazon ElastiCache is a fully managed implementation of two popular in- memory data stores – Redis and Memcached. The in-memory caching provided by ElastiCache can be used to significantly improve latency and throughput for many read-heavy application workloads or compute-intensive workloads.
There are two types of engine you can choose :
Memcached, Redis – MEMCACHED Simplest model and can run large nodes. Can be scaled in and out and cache objects such as DBs. Widely adopted memory object caching system.
Multi-threaded. Redis Open-source in-memory key-value store. Supports more complex data structures: sorted sets and lists. Supports master / slave replication and multi-AZ for cross-AZ redundancy. Support automatic failover and backup/restore.
As the Developer requires a multi-threaded cache, the best choice is Memcached.
CORRECT: “Amazon ElastiCache Memcached” is the correct answer.
INCORRECT: “Amazon ElastiCache Redis” is incorrect as Redis it not multi-threaded.
INCORRECT: “Amazon DynamoDB DAX” is incorrect as this is more suitable for use with an Amazon DynamoDB table.
INCORRECT: “Amazon RedShift” is incorrect as this is not an in-memory caching engine, it is a data warehouse.
Question
A Developer needs to write a small amount of temporary log files from an application running on an Amazon EC2 instance. The log files will be automatically deleted every 24 hours. What is the SIMPLEST solution for storing this data that will not require additional code?
1: Write the log files to an attached Amazon EBS volume 2: Write the log files to an Amazon EFS volume
3: Write the log files to an Amazon DynamoDB database 4: Write the log files to an Amazon S3 bucket
Answer: 1
Explanation:
Amazon Elastic Block Store (Amazon EBS) provides block level storage volumes for use with EC2 instances. EBS volumes behave like raw, unformatted block devices.
You can mount these volumes as devices on your instances. You can mount multiple volumes on the same instance, and you can mount a volume to multiple instances at a time.
You can create a file system on top of these volumes or use them in any way
you would use a block device (like a hard drive). You can dynamically change the configuration of a volume attached to an instance.
The simplest solution for this scenario is to choose a local Elastic Block Store (EBS) volume to write the log files to. This requires no additional coding.
CORRECT: “Write the log files to an attached Amazon EBS volume” is the correct answer.
INCORRECT: “Write the log files to an Amazon EFS volume” is incorrect as this is not the simplest solution and is better suited to use cases where you need to share the data with other instances.
INCORRECT: “Write the log files to an Amazon DynamoDB database” is incorrect as this is not the simplest solution as it would require additional code in the application compared to just writing the data to a local volume. INCORRECT: “Write the log files to an Amazon S3 bucket” is incorrect as this is not the simplest solution as it would require additional code in the application compared to just writing the data to a local volume.
Question
A Developer has recently created an application that uses an AWS Lambda function, an Amazon DynamoDB table, and also sends notifications using Amazon SNS. The application is not working as expected and the Developer needs to analyze what is happening across all components of the application. What is the BEST way to analyze the issue?
1: Enable X-Ray tracing for the Lambda function
2: Create an Amazon CloudWatch Events rule
3: Assess the application with Amazon Inspector
4: Monitor the application with AWS Trusted Advisor
Answer: 1
Explanation:
AWS X-Ray makes it easy for developers to analyze the behavior of their production, distributed applications with end-to-end tracing capabilities. You can use X-Ray to identify performance bottlenecks, edge case errors, and other hard-to-detect issues.
AWS X-Ray provides an end-to-end, cross-service view of requests made to your application. It gives you an application-centric view of requests flowing
through your application by aggregating the data gathered from individual services in your application into a single unit called a trace. You can use this trace to follow the path of an individual request as it passes through each service or tier in your application so that you can pinpoint where issues are occurring.
AWS X-Ray will assist the developer with visually analyzing the end-to-end view of connectivity between the application components and how they are performing using a Service Map. X-Ray also provides aggregated data about the application.
CORRECT: “Enable X-Ray tracing for the Lambda function” is the correct answer.
INCORRECT: “Create an Amazon CloudWatch Events rule” is incorrect as this feature of CloudWatch is used to trigger actions based on changes in the state of AWS services.
INCORRECT: “Assess the application with Amazon Inspector” is incorrect. Amazon Inspector is an automated security assessment service that helps improve the security and compliance of applications deployed on AWS. INCORRECT: “Monitor the application with AWS Trusted Advisor” is incorrect. AWS Trusted Advisor is an online tool that provides you real time guidance to help you provision your resources following AWS best practices.
Question
A company needs to store sensitive documents on Amazon S3. The documents should be encrypted in transit using SSL/TLS and then be encrypted for storage at the destination. The company do not want to manage any of the encryption infrastructure or customer master keys and require the most cost-effective solution. What is the MOST suitable option to encrypt the data?
1: Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)
2: Server-Side Encryption with Customer Master Keys (CMKs) Stored in AWS Key Management Service (SSE-KMS) using customer managed CMKs 3: Server-Side Encryption with Customer-Provided Keys (SSE-C)
4: Client-side encryption with Amazon S3 managed keys
Answer: 1
Explanation:
Server-side encryption is the encryption of data at its destination by the application or service that receives it. Amazon S3 encrypts your data at the object level as it writes it to disks in its data centers and decrypts it for you when you access it. As long as you authenticate your request and you have access permissions, there is no difference in the way you access encrypted or unencrypted objects.
There are three options for server-side encryption:
Server-Side Encryption with Amazon S3-Managed Keys (SSE- S3) – the data is encrypted by Amazon S3 using keys that are managed through S3
Server-Side Encryption with Customer Master Keys (CMKs) Stored in AWS Key Management Service (SSE-KMS) – this options uses CMKs managed in AWS KMS. There are additional benefits such as auditing and permissions associated with the CMKs but also additional charges
Server-Side Encryption with Customer-Provided Keys (SSE- C) – you manage the encryption keys and Amazon S3 manages the encryption, as it writes to disks, and decryption, when you access your objects.
The most suitable option for the requirements in this scenario is to use Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) as the company do not want to manage CMKs and require a simple solution.
CORRECT: “Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)” is the correct answer.
INCORRECT: “Server-Side Encryption with Customer Master Keys (CMKs) Stored in AWS Key Management Service (SSE-KMS) using customer managed CMKs” is incorrect as the company do not want to manage CMKs and they need the most cost-effective option and this does add additional costs.
INCORRECT: “Server-Side Encryption with Customer-Provided Keys (SSE-C)” is incorrect as with this option the customer must manage the keys or use keys managed in AWS KMS (which adds cost and complexity).
INCORRECT: “Client-side encryption with Amazon S3 managed keys” is incorrect as you cannot use Amazon S3 managed keys for client-side encryption and the encryption does not need to take place client-side for this solution.
Question
A Developer is building a three-tier web application that must be able to handle a minimum of 10,000 requests per minute. The requirements state that the web tier should be completely stateless while the application maintains session state data for users. How can the session state data be maintained externally, whilst keeping latency at the LOWEST possible value?
1: Create an Amazon RedShift instance, then implement session handling at the application level to leverage a database inside the RedShift database instance for session data storage
2: Implement a shared Amazon EFS file system solution across the underlying Amazon EC2 instances, then implement session handling at the application level to leverage the EFS file system for session data storage
3: Create an Amazon ElastiCache Redis cluster, then implement session handling at the application level to leverage the cluster for session data storage
4: Create an Amazon DynamoDB table, then implement session handling at the application level to leverage the table for session data storage
Answer: 3
Explanation:
It is common to use key/value stores for storing session state data. The two options presented in the answers are Amazon DynamoDB and Amazon ElastiCache Redis. Of these two, ElastiCache will provide the lowest latency as it is an in-memory database.
Therefore, the best answer is to create an Amazon ElastiCache Redis cluster, then implement session handling at the application level to leverage the cluster for session data storage.
CORRECT: “Create an Amazon ElastiCache Redis cluster, then implement session handling at the application level to leverage the cluster for session data storage” is the correct answer.
INCORRECT: “Create an Amazon DynamoDB table, then implement session handling at the application level to leverage the table for session data storage” is incorrect as though this is a good solution for storing session state data, the latency will not be as low as with ElastiCache.
INCORRECT: “Create an Amazon RedShift instance, then implement session handling at the application level to leverage a database inside the RedShift database instance for session data storage” is incorrect. RedShift is a data warehouse that is used for OLAP use cases, not for storing session state data.
INCORRECT: “Implement a shared Amazon EFS file system solution across the underlying Amazon EC2 instances, then implement session handling at the application level to leverage the EFS file system for session data storage” is incorrect. For session state data a key/value store such as DynamoDB or ElastiCache will provide better performance.
Question
A Developer is writing an imaging microservice on AWS Lambda. The service is dependent on several libraries that are not available in the Lambda runtime environment. Which strategy should the Developer follow to create the Lambda deployment package?
1: Create a ZIP file with the source code and all dependent libraries 2: Create a ZIP file with the source code and a script that installs the dependent libraries at runtime
3: Create a ZIP file with the source code and an appspec.yml file. Add the libraries to the appspec.yml file and upload to Amazon S3. Deploy using CloudFormation
4: Create a ZIP file with the source code and a buildspec.yml file that installs the dependent libraries on AWS Lambda
Answer: 1
Explanation:
A deployment package is a ZIP archive that contains your function code and
dependencies. You need to create a deployment package if you use the Lambda API to manage functions, or if you need to include libraries and dependencies other than the AWS SDK.
You can upload the package directly to Lambda, or you can use an Amazon S3 bucket, and then upload it to Lambda. If the deployment package is larger than 50 MB, you must use Amazon S3.
CORRECT: “Create a ZIP file with the source code and all dependent libraries” is the correct answer.
INCORRECT: “Create a ZIP file with the source code and a script that installs the dependent libraries at runtime” is incorrect as the Developer should not run a script at runtime as this will cause latency. Instead, the Developer should include the dependent libraries in the ZIP package.
INCORRECT: “Create a ZIP file with the source code and an appspec.yml file. Add the libraries to the appspec.yml file and upload to Amazon S3.
Deploy using CloudFormation” is incorrect. The appspec.yml file is used with CodeDeploy, you cannot add libraries into it, and it is not deployed using CloudFormation.
INCORRECT: “Create a ZIP file with the source code and a buildspec.yml file that installs the dependent libraries on AWS Lambda” is incorrect as the buildspec.yml file is used with CodeBuild for compiling source code and running tests. It cannot be used to install dependent libraries within Lambda.
Question
An e-commerce web application that shares session state on-premises is being migrated to AWS. The application must be fault-tolerant, natively highly scalable, and any service interruption should not affect the user experience. What is the best option to store the session state?
1: Store the session state in Amazon ElastiCache 2: Store the session state in Amazon CloudFront 3: Store the session state in Amazon S3
4: Enable session stickiness using elastic load balancers
Answer: 1
Explanation:
There are various ways to manage user sessions including storing those sessions locally to the node responding to the HTTP request or designating a layer in your architecture which can store those sessions in a scalable and robust manner. Common approaches used include utilizing Sticky sessions or using a Distributed Cache for your session management.
In this scenario, a distributed cache is suitable for storing session state data. ElastiCache can perform this role and with the Redis engine replication is also supported. Therefore, the solution is fault-tolerant and natively highly scalable.
CORRECT: “Store the session state in Amazon ElastiCache” is the correct answer.
INCORRECT: “Store the session state in Amazon CloudFront” is incorrect as CloudFront is not suitable for storing session state data, it is used for caching content for better global performance.
INCORRECT: “Store the session state in Amazon S3” is incorrect as though you can store session data in Amazon S3 and replicate the data to another bucket, this would result in a service interruption if the S3 bucket was not accessible.
INCORRECT: “Enable session stickiness using elastic load balancers” is incorrect as this feature directs sessions from a specific client to a specific EC2 instances. Therefore, if the instance fails the user must be redirected to another EC2 instance and the session state data would be lost.
Question
A Developer is writing a serverless application that will process data uploaded to a file share. The Developer has created an AWS Lambda function and requires the function to be invoked every 15 minutes to process the data. What is an automated and serverless way to trigger the function?
1: Deploy an Amazon EC2 instance based on Linux, and edit it’s /etc/crontab file by adding a command to periodically invoke the Lambda function
2: Configure an environment variable named PERIOD for the Lambda function. Set the value at 600
3: Create an Amazon CloudWatch Events rule that triggers on a regular schedule to invoke the Lambda function
4: Create an Amazon SNS topic that has a subscription to the Lambda function with a 600-second timer
Answer: 3
Explanation:
Amazon CloudWatch Events help you to respond to state changes in your AWS resources. When your resources change state, they automatically send events into an event stream. You can create rules that match selected events in the stream and route them to your AWS Lambda function to take action.
You can create a Lambda function and direct AWS Lambda to execute it on a regular schedule. You can specify a fixed rate (for example, execute a Lambda function every hour or 15 minutes), or you can specify a Cron expression.
Therefore, the Developer should create an Amazon CloudWatch Events rule that triggers on a regular schedule to invoke the Lambda function. This is a serverless and automated solution.
CORRECT: “Create an Amazon CloudWatch Events rule that triggers on a regular schedule to invoke the Lambda function” is the correct answer.
INCORRECT: “Deploy an Amazon EC2 instance based on Linux, and edit it’s /etc/crontab file by adding a command to periodically invoke the Lambda function” is incorrect as EC2 is not a serverless solution.
INCORRECT: “Configure an environment variable named PERIOD for the Lambda function. Set the value at 600” is incorrect as you cannot cause a Lambda function to execute based on a value in an environment variable.
INCORRECT: “Create an Amazon SNS topic that has a subscription to the Lambda function with a 600-second timer” is incorrect as SNS does not run on a timer, CloudWatch Events should be used instead.
Question
A Developer attempted to run an AWS CodeBuild project, and received an error. The error stated that the length of all environment variables exceeds the limit for the combined maximum of characters. What is the recommended solution?
1: Add the export LC_ALL=”en_US.utf8” command to the pre_build section to ensure POSIX localization
2: Use Amazon Cognito to store key-value pairs for large numbers of environment variables
3: Update the settings for the build project to use an Amazon S3 bucket for large numbers of environment variables
4: Use AWS Systems Manager Parameter Store to store large numbers of environment variables
Answer: 4
Explanation:
In this case the build is using environment variables that are too large for
AWS CodeBuild. CodeBuild can raise errors when the length of all environment variables (all names and values added together) reach a combined maximum of around 5,500 characters.
The recommended solution is to use Amazon EC2 Systems Manager Parameter Store to store large environment variables and then retrieve them from your buildspec file. Amazon EC2 Systems Manager Parameter Store can store an individual environment variable (name and value added together) that is a combined 4,096 characters or less.
CORRECT: “Use AWS Systems Manager Parameter Store to store large numbers of environment variables” is the correct answer.
INCORRECT: “Add the export LC_ALL=”en_US.utf8” command to the pre_build section to ensure POSIX localization” is incorrect as this is used to set the locale and will not affect the limits that have been reached.
INCORRECT: “Use Amazon Cognito to store key-value pairs for large numbers of environment variables” is incorrect as Cognito is used for authentication and authorization and is not suitable for this purpose.
INCORRECT: “Update the settings for the build project to use an Amazon S3 bucket for large numbers of environment variables” is incorrect as Systems Manager Parameter Store is designed for this purpose and is a better fit.
Question
A Development team wants to run their container workloads on Amazon ECS. Each application container needs to share data with another container to collect logs and metrics. What should the Development team do to meet these requirements?
1: Create two pod specifications. Make one to include the application container and the other to include the other container. Link the two pods together
2: Create two task definitions. Make one to include the application container and the other to include the other container. Mount a shared volume between the two tasks
3: Create one task definition. Specify both containers in the definition. Mount a shared volume between those two containers
4: Create a single pod specification. Include both containers in the specification. Mount a persistent volume to both containers
Answer: 3
Explanation:
Amazon ECS tasks support Docker volumes. To use data volumes, you must specify the volume and mount point configurations in your task definition.
Docker volumes are supported for the EC2 launch type only.
To configure a Docker volume, in the task definition volumes section, define a data volume with name and DockerVolumeConfiguration values. In the containerDefinitions section, define multiple containers with mountPoints values that reference the name of the defined volume and the containerPath value to mount the volume at on the container.
The containers should both be specified in the same task definition. Therefore, the Development team should create one task definition, specify both containers in the definition and then mount a shared volume between those two containers
CORRECT: “Create one task definition. Specify both containers in the definition. Mount a shared volume between those two containers” is the correct answer.
INCORRECT: “Create two pod specifications. Make one to include the application container and the other to include the other container. Link the two pods together” is incorrect as pods are a concept associated with the Elastic Kubernetes Service (EKS).
INCORRECT: “Create two task definitions. Make one to include the application container and the other to include the other container. Mount a shared volume between the two tasks” is incorrect as a single task definition should be created with both containers.
INCORRECT: “Create a single pod specification. Include both containers in the specification. Mount a persistent volume to both containers” is incorrect as pods are a concept associated with the Elastic Kubernetes Service (EKS).
Question
An application deployed on AWS Elastic Beanstalk experienced increased error rates during deployments of new application versions, resulting in service degradation for users. The Development team believes that this is because of the reduction in capacity during the deployment steps. The team would like to change the deployment policy configuration of the environment to an option that maintains full
capacity during deployment while using the existing instances. Which deployment policy will meet these requirements while using the existing instances?
1: All at once 2: Rolling
3: Rolling with additional batch
4: Immutable
Answer: 3
Explanation:
AWS Elastic Beanstalk provides several options for how deployments are
processed, including deployment policies and options that let you configure batch size and health check behavior during deployments.
All at once:
Deploys the new version to all instances simultaneously.
Rolling:
Update a few instances at a time (bucket), and then move onto the next bucket once the first bucket is healthy (downtime for 1 bucket at a time).
Rolling with additional batch:
Like Rolling but launches new instances in a batch ensuring that there is full availability.
Immutable:
Launches new instances in a new ASG and deploys the version update to these instances before swapping traffic to these instances once healthy.
Zero downtime.
Blue / Green deployment:
Zero downtime and release facility.
Create a new “stage” environment and deploy updates there.
The rolling with additional batch launches a new batch to ensure capacity is
not reduced and then updates the existing instances. Therefore, this is the best option to use for these requirements.
CORRECT: “Rolling with additional batch” is the correct answer.
INCORRECT: “Rolling” is incorrect as this will only use the existing instances without introducing an extra batch and therefore this will reduce the capacity of the application while the updates are taking place.
INCORRECT: “All at once” is incorrect as this will run the updates on all instances at the same time causing a total outage.
INCORRECT: “Immutable” is incorrect as this installs the updates on new instances, not existing instances.
Question
A company has implemented AWS CodePipeline to automate its release pipelines. The Development team is writing an AWS Lambda function that will send notifications for state changes of each of the actions in the stages. Which steps must be taken to associate the Lambda function with the event source?
1: Create a trigger that invokes the Lambda function from the Lambda console by selecting CodePipeline as the event source
2: Create an event trigger and specify the Lambda function from the CodePipeline console
3: Create an Amazon CloudWatch alarm that monitors status changes in CodePipeline and triggers the Lambda function
4: Create an Amazon CloudWatch Events rule that uses CodePipeline as an event source
Answer: 4
Explanation:
Amazon CloudWatch Events help you to respond to state changes in your AWS resources. When your resources change state, they automatically send events into an event stream. You can create rules that match selected events in the stream and route them to your AWS Lambda function to take action. AWS CodePipeline can be configured as an event source in CloudWatch
Events and can then send notifications using as service such as Amazon SNS. Therefore, the best answer is to create an Amazon CloudWatch Events rule that uses CodePipeline as an event source.
CORRECT: “Create an Amazon CloudWatch Events rule that uses CodePipeline as an event source” is the correct answer.
INCORRECT: “Create a trigger that invokes the Lambda function from the Lambda console by selecting CodePipeline as the event source” is incorrect as CodePipeline cannot be configured as a trigger for Lambda.
INCORRECT: “Create an event trigger and specify the Lambda function from the CodePipeline console” is incorrect as CodePipeline cannot be configured as a trigger for Lambda.
INCORRECT: “Create an Amazon CloudWatch alarm that monitors status changes in CodePipeline and triggers the Lambda function” is incorrect as CloudWatch Events is used for monitoring state changes.
Question
A Developer has made an update to an application. The application serves users around the world and uses Amazon CloudFront for caching content closer to users. It has been reported that after deploying the application updates, users are not able to see the latest changes. How can the Developer resolve this issue?
1: Remove the origin from the CloudFront configuration and add it again 2: Disable forwarding of query strings and request headers from the CloudFront distribution configuration
3: Invalidate all the application objects from the edge caches
4: Disable the CloudFront distribution and enable it again to update all the edge locations
Answer: 3
Explanation:
If you need to remove a file from CloudFront edge caches before it expires, you can do one of the following:
Invalidate the file from edge caches. The next time a viewer requests the file, CloudFront returns to the origin to fetch the latest version of the file.
Use file versioning to serve a different version of the file that has a different name.
In this case, the best option available is to invalidate all the application objects from the edge caches. This will result in the new objects being cached next time a request is made for them.
CORRECT: “Invalidate all the application objects from the edge caches” is the correct answer.
INCORRECT: “Remove the origin from the CloudFront configuration and add it again” is incorrect as this is going to cause all objects to be removed and then recached which is overkill and will cost more.
INCORRECT: “Disable forwarding of query strings and request headers from the CloudFront distribution configuration” is incorrect as this is not a way to invalidate objects in Amazon CloudFront.
INCORRECT: “Disable the CloudFront distribution and enable it again to update all the edge locations” is incorrect as this will not cause the objects to expire, they will expire whenever their expiration date occurs and must be invalidated to make this happen sooner.
Question
A company has three different environments: Development, QA, and Production. The company wants to deploy its code first in the Development environment, then QA, and then Production. Which AWS service can be used to meet this requirement?
1: Use AWS CodeCommit to create multiple repositories to deploy the application
2: Use AWS CodeBuild to create, configure, and deploy multiple build application projects
3: Use AWS Data Pipeline to create multiple data pipeline provisions to deploy the application
4: Use AWS CodeDeploy to create multiple deployment groups
Answer: 4
Explanation:
You can specify one or more deployment groups for a CodeDeploy application. Each application deployment uses one of its deployment groups. The deployment group contains settings and configurations used during the deployment.
You can associate more than one deployment group with an application in CodeDeploy. This makes it possible to deploy an application revision to different sets of instances at different times. For example, you might use one deployment group to deploy an application revision to a set of instances tagged Tests where you ensure the quality of the code.
Next, you deploy the same application revision to a deployment group with instances tagged Staging for additional verification. Finally, when you are ready to release the latest application to customers, you deploy to a deployment group that includes instances tagged Production.
Therefore, using AWS CodeDeploy to create multiple deployment groups can be used to meet the requirement
CORRECT: “Use AWS CodeDeploy to create multiple deployment groups” is the correct answer.
INCORRECT: “Use AWS CodeCommit to create multiple repositories to deploy the application” is incorrect as the requirement is to deploy the same code to separate environments in a staged manner. Therefore, having multiple code repositories is not useful.
INCORRECT: “Use AWS CodeBuild to create, configure, and deploy multiple build application projects” is incorrect as the requirement is not to build the application, it is to deploy the application.
INCORRECT: “Use AWS Data Pipeline to create multiple data pipeline provisions to deploy the application” is incorrect as Data Pipeline is a service used for data migration, not deploying updates to applications.
Question
A Developer has been tasked by a client to create an application. The client has provided the following requirements for the application:
Performance efficiency of seconds with up to a minute of latency
Data storage requirements will be up to thousands of terabytes Per-message sizes may vary between 100 KB and 100 MB Data can be stored as key/value stores supporting eventual consistency
What is the MOST cost-effective AWS service to meet these requirements?
1: Amazon DynamoDB
3: Amazon S3
3: Amazon RDS (with a MySQL engine) 4: Amazon ElastiCache
Answer: 2
Explanation:
The question is looking for a cost-effective solution. Multiple options can support the latency and scalability requirements. Amazon RDS is not a key/value store so that rules that option out. Of the remaining options ElastiCache would be expensive and DynamoDB only supports a maximum item size of 400 KB. Therefore, the best option is Amazon S3 which delivers all of the requirements.
CORRECT: “Amazon S3” is the correct answer.
INCORRECT: “Amazon DynamoDB” is incorrect as it supports a maximum item size of 400 KB and the messages will be up to 100 MB.
INCORRECT: “Amazon RDS (with a MySQL engine)” is incorrect as it is not a key/value store.
INCORRECT: “Amazon ElastiCache” is incorrect as it is an in-memory database and would be the most expensive solution.
Question
An application on-premises uses Linux servers and a relational database using PostgreSQL. The company will be migrating the application to AWS and require a managed service that will take care of capacity provisioning, load balancing, and auto-scaling. Which combination of services should the Developer use? (Select TWO)
1: AWS Elastic Beanstalk
2: Amazon EC2 with Auto Scaling 3: Amazon EC2 with PostgreSQL 4: Amazon RDS with PostrgreSQL
5: AWS Lambda with CloudWatch Events
Answer: 1,4
Explanation:
The company require a managed service therefore the Developer should choose to use Elastic Beanstalk for the compute layer and Amazon RDS with the PostgreSQL engine for the database layer.
AWS Elastic Beanstalk will handle all capacity provisioning, load balancing, and auto-scaling for the web front-end and Amazon RDS provides push- button scaling for the backend.
CORRECT: “AWS Elastic Beanstalk” is a correct answer.
CORRECT: “Amazon RDS with PostrgreSQL” is also a correct answer.
INCORRECT: “Amazon EC2 with Auto Scaling” is incorrect as though these services will be used to provide the automatic scalability required for the solution, they still need to be managed. The questions asks for a managed solution and Elastic Beanstalk will manage this for you. Also, there is no mention of a load balancer so connections cannot be distributed to instances.
INCORRECT: “Amazon EC2 with PostgreSQL” is incorrect as the question asks for a managed service and therefore the database should be run on Amazon RDS.
INCORRECT: “AWS Lambda with CloudWatch Events” is incorrect as there is no mention of refactoring application code to run on AWS Lambda.
Question
A company runs many microservices applications that use Docker containers. The company are planning to migrate the containers to Amazon ECS. The workloads are highly variable and therefore the company prefers to be charged per running task. Which solution is the BEST fit for the company’s requirements?
1: Amazon ECS with the EC2 launch type
2: Amazon ECS with the Fargate launch type 3: An Amazon ECS Service with Auto Scaling 4: An Amazon ECS Cluster with Auto Scaling
Answer: 2
Explanation:
The key requirement is that the company should be charged per running task.
Therefore, the best answer is to use Amazon ECS with the Fargate launch type as with this model AWS charge you for running tasks rather than running container instances.
The Fargate launch type allows you to run your containerized applications without the need to provision and manage the backend infrastructure. You just register your task definition and Fargate launches the container for you. The Fargate Launch Type is a serverless infrastructure managed by AWS. CORRECT: “Amazon ECS with the Fargate launch type” is the correct answer.
INCORRECT: “Amazon ECS with the EC2 launch type” is incorrect as with this launch type you pay for running container instances (EC2 instances).
INCORRECT: “An Amazon ECS Service with Auto Scaling” is incorrect as this does not specify the launch type. You can run an ECS Service on the Fargate or EC2 launch types.
INCORRECT: “An Amazon ECS Cluster with Auto Scaling” is incorrect as this does not specify the launch type. You can run an ECS Cluster on the Fargate or EC2 launch types.
Question
A team of Developers require read-only access to an Amazon DynamoDB table. The Developers have been added to a group. What should an administrator do to provide the team with access whilst following the principal of least privilege?
1: Assign the AmazonDynamoDBReadOnlyAccess AWS managed policy to the group
2: Create a customer managed policy with read only access to DynamoDB and specify the ARN of the table for the “Resource” element. Attach the policy to the group
3: Assign the AWSLambdaDynamoDBExecutionRole AWS managed policy to the group
4: Create a customer managed policy with read/write access to DynamoDB for all resources. Attach the policy to the group
Answer: 2
Explanation:
The key requirement is to provide read-only access to the team for a specific DynamoDB table. Therefore, the AWS managed policy cannot be used as it will provide access to all DynamoDB tables in the account which does not follow the principal of least privilege.
Therefore, a customer managed policy should be created that provides read- only access and specifies the ARN of the table. For instance, the resource element might include the following ARN:
arn:aws:dynamodb:us-west-1:515148227241:table/exampletable This will lock down access to the specific DynamoDB table, following the principal of least privilege.
CORRECT: “Create a customer managed policy with read only access to DynamoDB and specify the ARN of the table for the “Resource” element. Attach the policy to the group” is the correct answer.
INCORRECT: “Assign the AmazonDynamoDBReadOnlyAccess AWS managed policy to the group” is incorrect as this will provide read-only access to all DynamoDB tables in the account.
INCORRECT: “Assign the AWSLambdaDynamoDBExecutionRole AWS managed policy to the group” is incorrect as this is a role used with AWS Lambda.
INCORRECT: “Create a customer managed policy with read/write access to DynamoDB for all resources. Attach the policy to the group” is incorrect as read-only access should be provided, not read/write.
Question
A Developer is reviewing the permissions attached to an AWS Lambda function’s execution role. What are the minimum permissions required for Lambda to create an Amazon CloudWatch Logs group and stream and write logs into the stream?
1: “logs:CreateLogGroup”, “logs:CreateLogStream”, “logs:PutLogEvents” 2: “logs:CreateLogGroup”, “logs:CreateLogStream”, “logs:PutDestination” 3: “logs:CreateExportTask”, “logs:CreateLogStream”, “logs:PutLogEvents” 4: “logs:GetLogEvents”, “logs:GetLogRecord”, “logs:PutLogEvents”
Answer: 1
Explanation:
The minimum permissions required are as follows: “logs:CreateLogGroup” – Creates a log group with the specified name.
“logs:CreateLogStream” – Creates a log stream for the specified log group.
“logs:PutLogEvents” – Uploads a batch of log events to the specified log stream.
CORRECT: ““logs:CreateLogGroup”, “logs:CreateLogStream”, “logs:PutLogEvents”” is the correct answer.
INCORRECT: ““logs:CreateLogGroup”, “logs:CreateLogStream”, “logs:PutDestination”” is incorrect as PutDestination creates or updates a destination.
INCORRECT: ““logs:CreateExportTask”, “logs:CreateLogStream”, “logs:PutLogEvents”” is incorrect as CreateExportTask creates an export task, which allows you to efficiently export data from a log group to an Amazon S3 bucket.
INCORRECT: ““logs:GetLogEvents”, “logs:GetLogRecord”, “logs:PutLogEvents”” is incorrect as all permissions are incorrect.
Question
An application needs to generate SMS text messages and emails for a large number of subscribers. Which AWS service can be used to send these messages to customers?
1: Amazon SES
2: Amazon SQS
3: Amazon SWF
4: Amazon SNS
Answer: 4
Explanation:
Amazon Simple Notification Service (Amazon SNS) is a web service that coordinates and manages the delivery or sending of messages to subscribing endpoints or clients. In Amazon SNS, there are two types of clients— publishers and subscribers—also referred to as producers and consumers.
Publishers communicate asynchronously with subscribers by producing and sending a message to a topic, which is a logical access point and communication channel.
Subscribers (that is, web servers, email addresses, Amazon SQS queues,
AWS Lambda functions) consume or receive the message or notification over one of the supported protocols (that is, Amazon SQS, HTTP/S, email, SMS, Lambda) when they are subscribed to the topic.
CORRECT: “Amazon SNS” is the correct answer.
INCORRECT: “Amazon SES” is incorrect as this service only sends email, not SMS text messages.
INCORRECT: “Amazon SQS” is incorrect as this is a hosted message queue for decoupling application components.
INCORRECT: “Amazon SWF” is incorrect as the Simple Workflow Service is used for orchestrating multi-step workflows.
Question
A website is deployed in several AWS regions. A Developer needs to direct global users to the website that provides the best performance. How can the Developer achieve this?
1: Create Alias records in AWS Route 53 and direct the traffic to an Elastic Load Balancer
2: Create A records in AWS Route 53 and use a weighted routing policy
3: Create A records in AWS Route 53 and use a latency-based routing policy
4: Create CNAME records in AWS Route 53 and direct traffic to Amazon CloudFront
Answer: 3
Explanation:
If your application is hosted in multiple AWS Regions, you can improve performance for your users by serving their requests from the AWS Region that provides the lowest latency.
To use latency-based routing, you create latency records for your resources in multiple AWS Regions. When Route 53 receives a DNS query for your domain or subdomain (example.com or acme.example.com), it determines which AWS Regions you’ve created latency records for, determines which region gives the user the lowest latency, and then selects a latency record for that region. Route 53 responds with the value from the selected record, such as the IP address for a web server.
CORRECT: “Create A records in AWS Route 53 and use a latency-based routing policy” is the correct answer.
INCORRECT: “Create Alias records in AWS Route 53 and direct the traffic to an Elastic Load Balancer” is incorrect as an ELB is within a single region. In this case the Developer needs to direct traffic to different regions.
INCORRECT: “Create A records in AWS Route 53 and use a weighted routing policy” is incorrect as weighting is used to send more traffic to one region other another, not to direct for best performance.
INCORRECT: “Create CNAME records in AWS Route 53 and direct traffic to Amazon CloudFront” is incorrect as this does not direct traffic to different regions for best performance which is what the questions asks for.
Question
An IAM user is unable to assume an IAM role. The policy statement includes the “Effect”: “Allow” and “Resource”: “arn:aws:iam::5123399432:role/MyCARole” elements. Which other element MUST be included to allow the role to be assumed?
1: “Action”: “ec2:AssumeRole
2: “Action”: “sts:AssumeRole”
3: “Action”: “sts:GetSessionToken”
4: “Action”: “sts:GetAccessKeyInfo”
Answer: 2
Explanation:
The user needs to verify that the IAM policy grants permission to
call sts:AssumeRole for the role that they want to assume.
The Action element of an IAM policy must allow you to call
the AssumeRole action. In addition, the Resource element of your IAM policy must specify the role that you want to assume.
For this situation the IAM policy would need to include a statement such as this:
“Effect”: “Allow”,
“Action”: “sts:AssumeRole”,
“Resource”: “arn:aws:iam::5123399432:role/MyCARole”
CORRECT: “”Action”: “sts:AssumeRole”” is the correct answer.
INCORRECT: “”Action”: “ec2:AssumeRole”” is incorrect as the security token service (STS) is used for assuming roles.
INCORRECT: “”Action”: “sts:GetSessionToken”” is incorrect as this API action returns a set of temporary credentials for an AWS account or IAM user.
INCORRECT: “”Action”: “sts:GetAccessKeyInfo”” is incorrect as this API Action returns the account identifier for the specified access key ID.
Question
An existing IAM user needs access to AWS resources in another account from an insecure environment for a short-term need (around 15 minutes). What would be the MOST secure method to provide the required access?
1: Use the AssumeRoleWithWebIdentity API operation to assume a role in the other account that has the required permissions
2: Use the AssumeRole API operation to assume a role in the other account that has the required permissions
3: Use the GetFederationToken API operation to return a set of temporary security credentials
4: Use the GetSessionToken API operation to return a set of temporary security credentials and specify 900 seconds in the DurationSeconds parameter
Answer: 4
Explanation:
The GetSessionToken API operation returns a set of temporary security credentials to an existing IAM user. This is useful for providing enhanced security, such as allowing AWS requests only when MFA is enabled for the IAM user.
Because the credentials are temporary, they provide enhanced security when you have an IAM user who accesses your resources through a less secure environment. Examples of less secure environments include a mobile device or web browser.
By default, temporary security credentials for an IAM user are valid for a maximum of 12 hours. But you can request a duration as short as 15 minutes or as long as 36 hours using the DurationSeconds parameter.
GetSessionToken returns temporary security credentials consisting of a security token, an access key ID, and a secret access key.
CORRECT: “Use the GetSessionToken API operation to return a set of temporary security credentials and specify 900 seconds in the DurationSeconds parameter” is the correct answer.
INCORRECT: “Use the AssumeRoleWithWebIdentity API operation to assume a role in the other account that has the required permissions” is incorrect as this is used for federated users who are authenticated through a public identity provider.
INCORRECT: “Use the AssumeRole API operation to assume a role in the other account that has the required permissions” is incorrect as the without correct answer includes the DurationSeconds parameter which can be used to specify how long the credentials last. That is a more secure option and could also be used with AssumeRole but wasn’t included with this option.
INCORRECT: “Use the GetFederationToken API operation to return a set of temporary security credentials” is incorrect.
Question
A Developer has created a task definition that includes the following JSON code:
“placementStrategy”: [{“field”: “attribute:ecs.availability-zone”, “type”: “spread”},{“field”: “instanceId”, “type”: “spread”}]
What is the effect of this task placement strategy?
1: It distributes tasks evenly across Availability Zones and then distributes tasks evenly across the instances within each Availability Zone
2: It distributes tasks evenly across Availability Zones and then bin packs tasks based on memory within each Availability Zone
3: It distributes tasks evenly across Availability Zones and then distributes tasks evenly across distinct instances within each Availability Zone
4: It distributes tasks evenly across Availability Zones and then distributes tasks randomly across instances within each Availability Zone
Answer: 1
Explanation:
A task placement strategy is an algorithm for selecting instances for task placement or tasks for termination. Task placement strategies can be specified when either running a task or creating a new service.
Amazon ECS supports the following task placement strategies:
binpack – Place tasks based on the least available amount of CPU or memory. This minimizes the number of instances in use.
random – Place tasks randomly.
spread – Place tasks evenly based on the specified value. Accepted values are instanceId (or host, which has the same effect), or any platform or custom attribute that is applied to a container instance, such as attribute:ecs.availability-zone.
You can specify task placement strategies with the following actions: CreateService, UpdateService, and RunTask. You can also use multiple strategies together as in the example JSON code provided with the question.
CORRECT: “It distributes tasks evenly across Availability Zones and then distributes tasks evenly across the instances within each Availability Zone” is the correct answer.
INCORRECT: “It distributes tasks evenly across Availability Zones and then bin packs tasks based on memory within each Availability Zone” is incorrect as it does not use the binpack strategy.
INCORRECT: “It distributes tasks evenly across Availability Zones and then distributes tasks evenly across distinct instances within each Availability Zone” is incorrect as it does not spread tasks across distinct instances (use a task placement constraint).
INCORRECT: “It distributes tasks evenly across Availability Zones and then distributes tasks randomly across instances within each Availability Zone” is incorrect as it does not use the random strategy.
Question
What is the most suitable storage solution for files up to 1 GB in size that must be stored for long periods of time that are accessed directly by applications with varying frequency?
1: Amazon S3 Glacier 2: Amazon DynamoDB 3: Amazon S3 Standard 4: Amazon RDS
Answer: 3
Explanation:
S3 Standard offers high durability, availability, and performance object storage for frequently accessed data.
Key Features:
Low latency and high throughput performance
Designed for durability of 99.999999999% of objects across multiple Availability Zones
Resilient against events that impact an entire Availability Zone Designed for 99.99% availability over a given year Backed with the Amazon S3 Service Level Agreement for availability
Supports SSL for data in transit and encryption of data at rest S3 Lifecycle management for automatic migration of objects to other S3 Storage Classes
Amazon S3 Standard is the best solution for this scenario as the data is accessed directly by applications with varying frequency. Therefore, the S3 Glacier storage class would not be suitable as it would archive the data and data must be restored before being accessible.
CORRECT: “Amazon S3 Standard” is the correct answer.
INCORRECT: “Amazon S3 Glacier” is incorrect as it would archive the data and data must be restored before being accessible
INCORRECT: “Amazon DynamoDB” is incorrect as this is a database and
is not suitable for storing files of this size.
INCORRECT: “Amazon RDS” is incorrect as this a relational database and is not suitable for storing files.
Question
Users of an application using Amazon API Gateway, AWS Lambda and Amazon DynamoDB have reported errors when using the application.
Which metrics should a Developer monitor in Amazon CloudWatch to determine the number of client-side and server-side errors?
1: 4XXError and 5XXError
2: CacheHitCount and CacheMissCount 3: IntegrationLatency and Latency
4: Errors
Answer: 1
Explanation:
To determine the number of client-side errors captured in a given period the Developer should look at the 4XXError metric. To determine the number of server-side errors captured in a given period the Developer should look at the 5XXError.
CORRECT: “4XXError and 5XXError” is the correct answer.
INCORRECT: “CacheHitCount and CacheMissCount” is incorrect as these count the number of requests served from the cache and the number of requests served from the backend.
INCORRECT: “IntegrationLatency and Latency” is incorrect as these measure the amount of time between when API Gateway relays a request to the backend and when it receives a response from the backend and the time between when API Gateway receives a request from a client and when it returns a response to the client.
INCORRECT: “Errors” is incorrect as this is not a metric related to Amazon API Gateway.



